Binnen Unsupervised Learning werk je met niet-gelabelde data, waarbinnen je toch waardevolle patronen wilt kunnen ontdekken.
Denk hierbij bijvoorbeeld aan het volgende voorbeeld: Webshops kunnen gegevens van alle klanten verzamelen. Om meer te verkopen kan het helpen om gepersonaliseerde suggesties te doen, zodat je die ene toffe trui al te zien krijgt voordat je er zelf naar had gezocht. Door gebruikers met Machine Learning in een bepaald aantal groepen in te delen, zal elke groep die suggesties voor artikelen krijgen die voor de groep het meest relevant zijn. Hiervoor kun je Unsupervised Learning gebruiken.
Unsupervised Learning betekent letterlijk ongecontroleerd leren. Dit betekent dat je geen data tot je beschikking hebt om een voorspelling te valideren, waarmee je de betrouwbaarheid van voorspellingen kunt meten. Dit in tegenstelling tot Supervised Learning, waarbij je tijdens het trainen van een algoritme altijd de betrouwbaarheid kunt meten. Het is een concept uit het data science vakgebied.
Op hoofdniveau vallen er onder Unsupervised Learning 3 methoden, dit zijn:
- Unsupervised learning met clustering
- Unsupervised learning met Dimensionality Reduction
- Unsupervised learning met Pattern Search / Association Rule Learning
We gaan stap voor stap door deze verschillende methoden heen om de ins en outs te verduidelijken.
Unsupervised learning met clustering
Met clustering verdeel je de datapunten in je dataset in meerdere groepen. Dit lijkt op Classificatie uit Supervised Learning. Het verschil is dat je bij Classificatie de groepen vooraf al kende, waar je dit bij Clustering vooraf nog niet weet. Als voorbeeld kun je hierbij denken aan dat je je sokken op kleur gaat sorteren, maar nog niet weet welke kleuren je allemaal hebt.
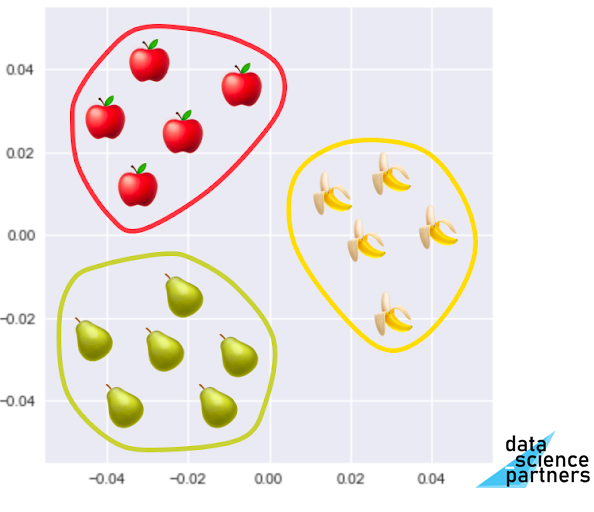
Clustering wordt door data scientists typisch gebruikt voor de volgende doeleinden:
- Marktsegmentatie: door jou als gebruiker in een groep te delen kun je een betere ervaring krijgen van een website (bijvoorbeeld een webshop zoals Bol.com)
- Compressie van afbeeldingen: gelijksoortige kleuren kunnen vervangen worden door de gemiddelde kleur uit de groep, waardoor minder gegevens nodig zijn en een afbeelding dus kleiner wordt
- Personalisering: naast personalisering in een eerder genoemde webshop wordt clustering bijvoorbeeld ook toegepast door bijvoorbeeld Apple en Google om je foto's automatisch te groeperen zodat je bijvoorbeeld een album hebt voor elk van je vrienden
Er zijn verschillende algoritmes waarmee je clustering toe kan passen. Voorbeelden hiervan zijn k-Means, Hierarchical Mean en Shift-Means. Met Python kun je deze algoritmes eenvoudig toepassen in een model. In Python zijn packages beschikbaar met functionaliteit die dit mogelijk maakt. We hebben hier een overzicht van data science packages gemaakt.
Unsupervised learning met Dimensionality Reduction
Het doel van Dimensionality Reduction is het reduceren van eigenschappen uit een dataset. Dit door meerdere bestaande eigenschappen samen te voegen in minder nieuwe eigenschappen. Denk hierbij als voorbeeld dat je alle honden met driehoekige oren, lange neuzen en lange staarten samenvat als herdershonden.
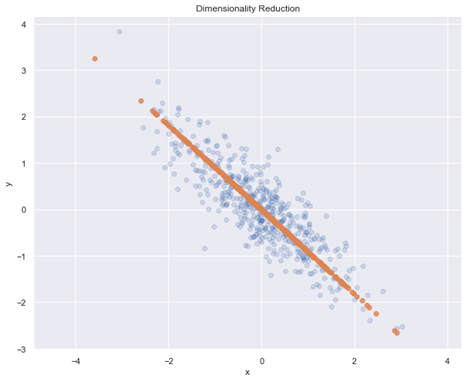
Dimensionality Reduction wordt in de praktijk gebruikt binnen bijvoorbeeld de volgende vakgebieden:
- Recommender Systems: Denk hierbij aan hoe je op Netflix, Amazon, Bol.com etc. continu gepersonaliseerde aanbevelingen krijgt voor andere producten
- Topic Modelling: Dit is te gebruiken om onder andere documenten en artikelen te groeperen op basis van het woordgebruik
Net als bij Clustering zijn er ook voor Dimensionality Reduction verschillende algoritmes te gebruiken. Veelgebruikte algoritmes zijn Principal Component Analysis (PCA), Singular Value Decomposition (SVD) en Latent Semantic Analysis (LSA, pLSA, GLSA).
Unsupervised learning met Pattern Search / Association Rule Learning
De laatste subgroep binnen Unsupervised Learning is de methode die Pattern Search of ook wel Association Rule Learning wordt genoemd. Deze methode wordt typisch gebruikt om onbekende onderliggende verbanden uit bijvoorbeeld transactionele data te verkrijgen. Denk hierbij aan het patroon dat als iemand een nieuw huis koopt, dat diegene dan ook nieuwe meubels zal gaan kopen.
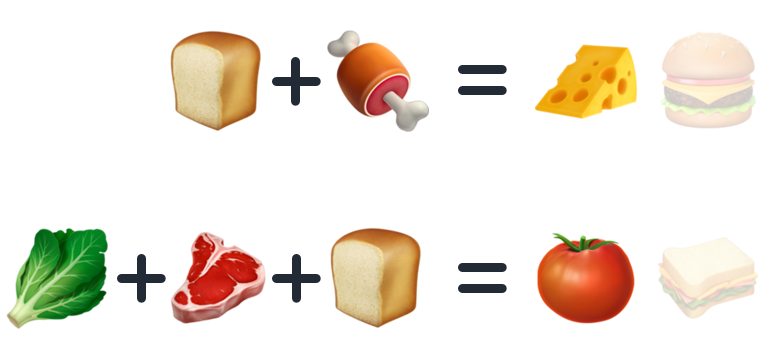
Praktische toepassingen van Pattern Search zijn zoal:
- Indeling van een (web)winkel: Welke samenstelling van producten kunnen het beste in het schap bij de kassa geplaatst worden voor maximale verkoop?
- Recommender System: Welk boek jou aangeraden wordt op Bol.com
De grote online tech bedrijven ontwikkelen hier veelal hun eigen algoritmes voor, maar bekende algoritmes omvatten: ECLAT (Equivalence Class Clustering and bottom-up Lattice Traversal), Apriori en FP-Growth.
Tot slot
We hebben geleerd dat Unsupervised Learning het samenstellen is van modellen zonder dat er data is om de kwaliteit van de voorspelling te valideren. Drie methoden binnen Unsupervised Learning zijn (1) Clustering, (2) Dimensionality Reduction en (3) Pattern Search / Association Rule Learning.
Unsupervised Learning met Python is onderdeel van onze data science opleiding en machine learning training. Dus wil jij je ontwikkelen of omscholen tot data scientist en in staat zijn om bijvoorbeeld een marktsegmentatie te doen met clustering? Schrijf je dan in of neem contact met ons op voor meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.