Classificatie is een machine learning methode binnen het gebied van supervised learning waarmee een categorie van een gegeven dataset voorspeld kan worden. Een categorie kan in deze context ook een class, label of target genoemd worden. Een voorbeeld van classificatie is spamdetectie in een mailbox. Hier zijn slechts 2 categorieën aanwezig: een e-mail is wel of geen spam.
Er zijn verschillende classificatie algoritmen die elk hun eigen specifieke kenmerken kennen. In deze tutorial gaan we nader in op het algoritme logistic regression. Logistic regression voorspelt de kans dat een datapunt bij een bepaalde categoriale waarde hoort. Hierbij is de categoriale waarde gelijk aan 1 (in geval van succes, bijvoorbeeld een spam e-mail) of 0 (geen succes, bijvoorbeeld een normale e-mail).
Het doel van deze tutorial is het vanuit scratch opbouwen van een classificatie model. Dit aan de hand van een begrijpbaar voorbeeld en in de volgende stappen:
- Importeer een dataset
- Dataset verkennen en opschonen
- Feature engineering
- Dataset opsplitsen in train en test data
- Machine learning model trainen en beoordelen
Importeer een dataset
Download de dataset: dataset voor deze tutorial
De dataset bevat data van een productiebedrijf wat unieke klantspecifieke artikelen maakt. In de praktijk komt het voor dat er bijvoorbeeld door een ontwerpfout tijdens het productieproces na werkzaamheden alsnog aanpassingen gemaakt moeten worden. Dit kost geld en tijd. Om kosten te minimaliseren is het belangrijk dat een artikel in één keer goed gemaakt wordt.
Om deze problemen te voorkomen wil het productiebedrijf op een vroegtijdig moment een voorspelling maken van welke artikelen een hoog risico bevatten op fouten. Het bedrijf houdt deze data al geruime tijd bij, en heeft zo een dataset opgebouwd van door klanten bestelde artikelen, met hierbij de aanduiding of het productieproces in één keer goed doorlopen is of niet. Dit wordt aangeduid als First Time Right (FTR).
Importeer de dataset door gebruik te maken van het package Pandas:
import pandas as pd
df = pd.read_excel('dataset_ftr_rates.xlsx')
df.shape
De dataset bevat leverdata van het productiebedrijf van een jaar. Het bevat 6,889 rijen en 15 kolommen. We kunnen nu kijken hoe de data eruit ziet:
De data in de verschillende kolommen bevat de volgende datatypes:
df.dtypes
De dataset bestaat uit inputvariabelen en outputvariabelen. Inputvariabelen omvat de data in kolommen die gebruikt kunnen worden om een voorspelling te geven van de outputvariabelen. In deze tutorial zijn er 14 inputvariabelen en is er 1 outputvariabele.
De inputvariabelen zijn:
- Ordernummer: een unieke code voor elke bestelling (string: ORD101125380, ORD101125381, ...)
- Ordertype: een code die aangeeft vanuit welke verkoopvestiging de order binnen is gekomen (integer: 10001, …, 10018)
- Klantnummer: unieke code voor iedere klant (integer: 103085, 103092, …)
- Land: land van de klant (categoriaal: NL, DE, …)
- Artikelnummer: een unieke code voor ieder uniek artikel (string: ifW7YxaomQ, tPzxpMPUc4, …)
- Volume: het berekende volume van het artikel (integer: 5, 6, …)
- Dichtheid: de berekende dichtheid van het artikel (float: 15.05, 15.23, …)
- Bewerkingen: het aantal bewerkingen wat in de fabriek nodig is om het artikel te maken (integer: 5, 8, …)
- Productcategorie: een code waarmee gelijksoortige artikelen zijn aangeduid (string: PROD10120, PROD10121)
- Hoeveelheid: de hoeveelheid waarin de klant dit artikel op deze order heeft besteld (integer: 1, 2, …)
- Artikelkostprijs: de berekende kostprijs van het artikel (float: 50.70, 1522.23, …)
- Verkoopbedrag: de prijs die de klant betaalt voor de bestelling (float: 16.45, 3223.66, …)
- Externe productie: geeft aan of er externe productie nodig is om dit artikel te kunnen maken, een 1 geeft aan dat dit nodig is (integer: 0, 1)
- Vraagdatum: de datum waarop de bestelling voor de klant beschikbaar moet zijn (datum: 6-1-2018, …)
Outputvariabele:
- FTR: First Time Right, geeft aan of de productie van een artikel in één keer goed is gegaan. Bij een waarde gelijk aan 1 is dit het geval (integer: 0, 1)
Dataset verkennen en opschonen
De dataset wordt verkend om eventuele relaties tussen inputvariabelen en de outputvariabele te leren kennen. Bij een aanwezig relatie is de kans groot dat deze variable goed gebruikt kan worden voor het machine learning model. De kwaliteit van data is belangrijk voor een nauwkeurige voorspelling. Daarom moet de dataset opgeschoond worden.
Met de volgende code worden statistieken van de kolommen met numerieke waarden getoond.
df.describe()
Hierbij valt het volgende op:
- Er komen artikelen voor met een negatief volume
- Er komen artikelen voor met een artikelkostprijs gelijk aan 0
- Er komen artikelen voor met een verkoopprijs gelijk aan 0
Gebaseerd op deze observaties filteren we rijen met negatieve volumes en artikelkostprijzen gelijk aan 0 uit. De rijen met een verkoopprijs gelijk aan 0 laten we staan, het kan immers dat een bestelling gratis geleverd wordt.
df = df[df['Artikelkostprijs'] != 0]
df = df[df['Volume'] > 0]
df.shape
Hiermee hebben we de dataset opgeschoond. Wees ervan bewust dat naast uitfilteren er meerdere methodes zijn voor het omgaan met vervuilde data. Zo hadden we bijvoorbeeld ook gemiddelde waarden in kunnen vullen of op logica gebaseerde invullingen kunnen doen.
Nu bekijken we de outputvariabele. Het is aannemelijk dat het grootste deel van de artikelen in één keer goed is gemaakt. We bekijken deze verdeling vanuit een countplot, wat de voorkomendheid van iedere unieke waarde in een kolom telt.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x = 'FTR',data = df)
plt.show()

Waarden in de kolom FTR gelijk aan 1 komen veel vaker voor dan waarden gelijk aan 0. Hieruit kan geconcludeerd worden dat het grootste deel van de artikelen inderdaad in één keer juist gemaakt wordt. De werkelijke verhouding kunnen we als volgt berekenen:
count_zeros = len(df[df['FTR'] == 0])
count_ones = len(df[df['FTR'] == 1])
ftr_percentage = count_ones / (count_zeros + count_ones)
print("First Time Right percentage:", round(ftr_percentage * 100, 1))
Van alle artikelen wordt 83.1% in één keer goed gemaakt, bij het overige deel is er iets fout gegaan.
De dataset kan gegroepeerd worden op de waarden in de FTR kolom, en van de overige numerieke kolommen kan hierbij het gemiddelde berekend worden. Dit geeft een eerste inzicht over eventuele verschillen per inputkolom gerelateerd aan de outputkolom.
df.groupby('FTR').mean()
Hierbij valt het volgende op:
- Volume, dichtheid, bewerkingen hoeveelheid en artikelkostprijs zijn gemiddeld iets lager bij een FTR gelijk aan 0
- Verkoopprijs en externe productie zijn gemiddeld iets hoger bij een FTR gelijk aan 0
Er zijn verschillende manieren om eventuele relaties tussen inputvariabelen en de outputvariabele inzichtelijk te maken, enkele zullen bekeken worden.
Bij kolommen met categoriale waarden zoals bijvoorbeeld het ordertype kan eerst de voorkomendheid bekeken worden.
pd.crosstab(df['Ordertype'],df['FTR']).plot(kind='bar')
plt.title('FTR frequency of ordertype')
plt.xlabel('Ordertype')
plt.ylabel('Frequency')

table=pd.crosstab(df['Ordertype'],df['FTR'])
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('FTR rate for each ordertype')
plt.xlabel('Ordertype')
plt.ylabel('FTR rate')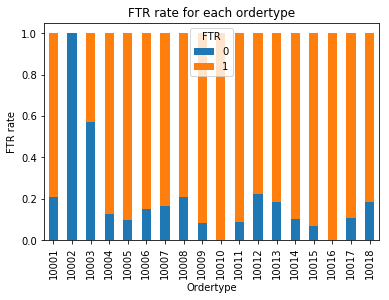
Het is nu duidelijk te zien dat artikelen van bepaalde ordertypes beter presteren dan anderen.
Inzicht in de waarden van een kolom met numerieke waarden kan met behulp van een histogram. We importeren tevens het package NumPy voor extra functionaliteit. Voor de verkoopprijs ziet dit er bijvoorbeeld als volgt uit:
import numpy as np
column = 'Verkoopprijs'
data = df[column].values
binwidth = 100
bins=np.arange(min(data), max(data) + binwidth, binwidth)
bins=np.arange(0, 1500 + binwidth, binwidth)
plt.hist(data, bins)
plt.title('Histogram column ' + column)
plt.xlabel(column)
plt.ylabel('Frequency')
plt.show()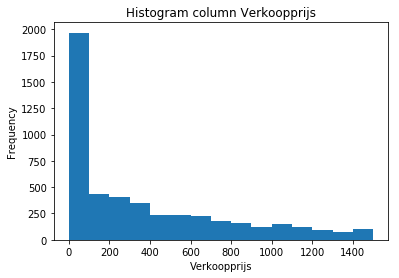
Te zien is dat er veel artikelen met een prijs tussen de 0 en 100 euro worden verkocht, en dat er een lange uitloop is naar duurdere artikelen.
Wanneer een histogram gemaakt wordt voor de kolom Bewerkingen is het volgende te zien:
column = 'Bewerkingen'
data = df[column].values
binwidth = 3
bins=np.arange(min(data), max(data) + binwidth, binwidth)
plt.hist(data, bins)
plt.title('Histogram van kolom ' + column)
plt.xlabel(column)
plt.ylabel('Frequency')
plt.show()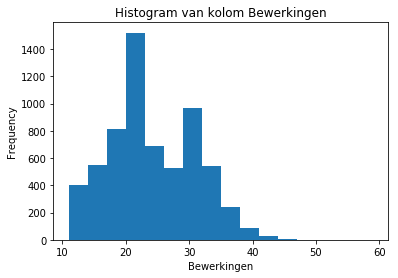
Hier lijkt het alsof er 2 normaalverdelingen te zien zijn. Dit duidt erop dat er artikelen op basis van het aantal bewerkingen wellicht in 2 aparte groepen verdeeld zou kunnen worden.
Dataset verkennen en opschonen
Feature engineering is het verrijken van een dataset met extra gegevens waardoor een Python machine learning model een betere voorspelperformance krijgt. Zojuist zagen we dat er 2 normaalverdelingen zichtbaar waren binnen de kolom Bewerkingen. We zouden nu een kolom toe kunnen voegen die op basis van het aantal bewerkingen een classificatie meegeeft.
df['class_bewerkingen'] = df['Bewerkingen'].apply(lambda x: 'simple' if x < 26 else 'complex')
Wanneer we deze nieuwe kolom relateren aan de output, FTR, zien we het volgende:
table=pd.crosstab(df['class_bewerkingen'],df['FTR'])
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('FTR rate for class_bewerkingen')
plt.xlabel('class_bewerkingen')
plt.ylabel('FTR rate')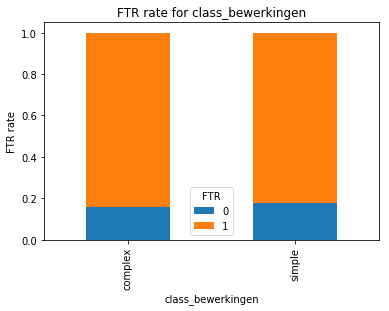
Er is hier geen duidelijk verschil te zien in FTR verhoudingen voor de twee categoriale waarden. Hierdoor zal deze nieuwe kolom naar verwachting weinig voorspellende waarde toevoegen.
In de dataset is kolom Vraagdatum aanwezig. Uit deze kolom is bijvoorbeeld de maand uit te datum apart in een kolom op te slaan:
df['month'] = df['Vraagdatum'].dt.month
Hiervan bekijken we ook weer de FTR verhoudingen:
table=pd.crosstab(df['month'],df['FTR'])
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('FTR rate per month')
plt.xlabel('Month')
plt.ylabel('FTR rate')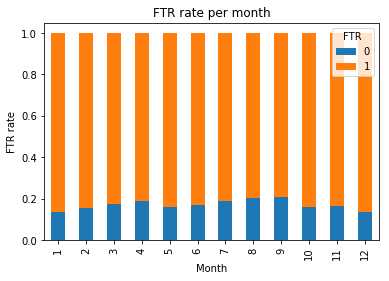
Hier is wel een verschil te zien in prestatie tussen de verschillende maanden. Er lijkt een soort seizoenscurve aanwezig te zijn. Waarschijnlijk zal deze kolom extra voorspellende waarde toevoegen voor het Python machine learning model.
Er zijn nog meer manieren om extra voorspellende waarde toe te voegen middels feature engineering. Denk aan het met logica combineren van verschillende kolommen, groeperen en samenvatten, en het toevoegen van data uit externe databronnen.
Gebaseerd op de bevindingen selecteren we nu de volgende kolommen om te gebruiken in het machine learning model:
columns = ['FTR',
'Ordertype',
'Klantnummer',
'Land',
'Volume',
'Dichtheid',
'Bewerkingen',
'Productcategorie',
'Hoeveelheid',
'Artikelkostprijs',
'Verkoopprijs',
'Externe productie',
'month']
df_model = df[columns].copy()
df_model.head()
Diverse van de kolommen die we willen gebruiken bevatten categoriale waarden. Hier kan een model niet direct mee omgaan. Omwille hiervan zetten we deze kolommen eerst om in numerieke waarden. Als voorbeeld voor de kolom Ordertype zal voor iedere unieke waarde een kolom toegevoegd worden, waarvan de waarde 1 is als dat ordertype in de rij van toepassing was, anders is de waarde 0.
def categorical_to_numerical(df, original_col_name):
for value in df[original_col_name].unique():
col_name = original_col_name + '_' + str(value)
df[col_name] = 0
df.loc[df[original_col_name] == value, col_name] = 1
df = df.drop([original_col_name], axis=1)
return df
columns = ['Ordertype',
'Klantnummer',
'Land',
'Productcategorie',
'Externe productie',
'month']
for feature in columns:
df_model = categorical_to_numerical(df_model, feature)
df_model.head()
De dataset bestaat nu volledig uit numerieke waarden. Het aantal kolommen is aanzienlijk verhoogd, naar 553. De dataset kan nu opgesplitst worden in train en test data.
Dataset opsplitsen in train en test data
De dataset voor een machine learning model wordt opgedeeld in train en test data. Train data is een willekeurig gekozen deel data (bijvoorbeeld 80% van de dataset) aan de hand waarvan het model de verbanden tussen inputs en output legt.
Het overige deel data is test data, dit wordt gebruikt om de voorspellingsprestatie van het model te meten. Deze data is immers nieuw voor het model en juist op deze data moet het model goed performen. Wanneer je dit niet valideert kan het voorkomen dat het model erg goed presteert op de data waarmee het is ingeleerd, maar waardeloos op nieuwe data.
De output bevindt zich in de eerste kolom, de overige kolommen zijn de voorspellende variabelen. We wijzen dit overeenkomstig toe en splitsen de dataset op. X waarden staan voor inputs, y waarden voor de output. De test_size geeft de verdeling aan tussen train en test data, een waarde van 0.2 betekent 20% testdata. De random_state is een vrij te kiezen waarde voor het willekeurig opsplitsen van de dataset. Door hier een waarde te kiezen zal de willekeurige opsplitsing iedere keer als je het script runt hetzelfde zijn.
from sklearn.model_selection import train_test_split
predictors = df_model.columns[1:]
output = df_model.columns[0]
X = df_model[predictors]
y = df_model[output]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=111)
Eerder hebben we gezien dat 83.1% van alle gemaakte artikelen in één keer goed was gemaakt. Dit betekent dat de dataset ongebalanceerd is: er zijn significant meer rijen van een bepaalde categorie aanwezig.
Door deze onbalans wordt het voor het model moeilijker om de juiste verbanden te ontdekken. Er zijn verschillende algoritmes beschikbaar die deze disbalans kunnen opheffen, we maken gebruik van SMOTE (Synthetic Minority Over-sampling Technique).
from imblearn.over_sampling import SMOTE
os = SMOTE(random_state=0)
X_train, y_train = os.fit_sample(X_train, y_train)
X_train = pd.DataFrame(data=X_train,columns=predictors )
y_train = pd.DataFrame(data=y_train,columns=[output])
Wanneer we nu een countplot maken zien we dat de dataset mooi gebalanceerd is.
sns.countplot(x = 'FTR', data = y_train)
plt.show()
De dataset is nu opgesplitst in train en test data en is gebalanceerd. Nu kan het model gemaakt, getraind en beoordeeld worden.
Machine learning model trainen en beoordelen
Allereerst moeten we een model aanmaken. Er zijn verschillende algoritmes voor classificatiemodellen. In deze tutorial kiezen we voor logistic regression uit package sklearn. Als het model aangemaakt is kan het getraind worden met de traindata, X_train en y_train.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
Het model is nu aangemaakt in getraind. Nu gebruiken we het model om de uitkomsten te gaan voorspellen voor de testdata, X_test. Ook berekenen we de kans voor elk van de uitkomsten, als in deze case de kans voor voor een bepaalde input gelijk is aan 0.90 betekent dit 90% zekerheid dat het artikel in één keer goed gemaakt zal worden in de fabriek.
y_pred = model.predict(X_test)
probabilities = model.predict_proba(X_test)
We hebben nu de uitkomsten voorspeld voor de testdata. Het is nu interessant om te zien hoe goed deze voorspelling is geweest. Dit doen we met behulp van meerdere metrics. Allereerst kijken we naar de accuracy:
import sklearn.metrics as sklm
accuracy = sklm.accuracy_score(y_test, y_pred)
print('Accuracy:', round(accuracy,3))
De accuracy, nauwkeurigheid, is gelijk aan 0.576. Dit betekent dat van alle voorspellingen er 57.6% juist zijn verricht.
Hier is meer detail in te verkrijgen, door te kijken naar de confusion matrix:
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print('Confusion matrix:\n', confusion_matrix)
TN, FP, FN, TP = confusion_matrix.ravel()
print("TN: {}, FP: {}, FN: {}, TP: {}\n".format(TN, FP, FN, TP))
Dit uitkomst kan als volgt geïnterpreteerd worden:
- Er zijn 120 + 105 rijen met een First Time Right gelijk aan 0, waarvan er 120 juist zijn voorspeld, en 105 onjuist
- Er zijn 435 + 614 rijen met een First Time Right gelijk aan 0, waarvan er 614 juist zijn voorspeld, en 435 onjuist
- Er zijn in totaal 120 + 614 voorspellingen juist, en 435 + 105 onjuist.
Vervolgens zijn deze gegevens weer samen te vatten in de metrics vanuit het sklearn classification report:
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print('Confusion matrix:\n', confusion_matrix)
TN, FP, FN, TP = confusion_matrix.ravel()
print("TN: {}, FP: {}, FN: {}, TP: {}\n".format(TN, FP, FN, TP))
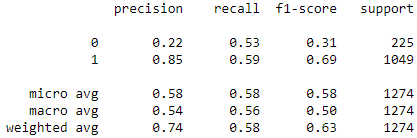
Hierin is het volgende te zien:
- Precision is de verhouding TP / (TP + FP), waar TP de het eerder berekende aantal True Positives is en FP het aantal False Positives. Precision weergeeft het vermogen van het model om een sample niet positief te classificeren waar het negatief is.
- Recall is de verhouding TP / (TP + FN), waar het aantal True Positives is en FN het aantal False Negatives. Recall weergeeft het vermogen van het model om alle positieve uitkomsten te vinden.
- F1-score weergeeft een gewogen harmonisch gemiddelde van precision en recall, waarbij een waarde van 1 het beste is een een waarde van 0 het slechtst.
- Support weergeeft het aantal rijen in de dataset per classificatie.
Hieruit is op te maken dat het model artikelen die in één keer goed gemaakt zijn behoorlijk goed kan voorspellen, maar dat het moeite heeft om artikelen die niet in één keer goed gemaakt zijn te herkennen. De prestatie van het model is hierdoor nog niet dermate goed dat het erg bruikbaar is.
Dit kunnen we ook zien met behulp van een ROC chart (Receiver Operating Characteristic), een veelgebruikt hulpmiddel bij classificatievraagstukken.
from sklearn.metrics import roc_curve, auc
def plot_auc(labels, probs):
# Calculate the ROC curve values and ROC area
fpr = dict()
tpr = dict()
roc_auc = dict()
fpr, tpr, _ = roc_curve(labels.values.ravel(), probs[:,1].ravel())
roc_auc = auc(fpr, tpr)
# Plot the result
plt.figure()
plt.plot(fpr, tpr, color = 'orange', label = 'AUC = %0.3f' % roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend()
plt.show()
plot_auc(y_test, probabilities)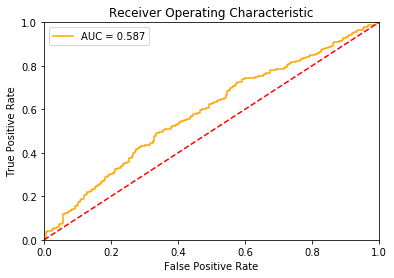
De gestippelde lijn weergeeft hier het geval van een volledig willekeurige classificatie. Een bruikbaar model moet uiteraard beter presteren dan het resultaat van willekeurig gokken.
Een goed classificatie model geeft een lijn die zo ver mogelijk van de stippellijn vandaan ligt, naar de richting van de linker bovenhoek. AUC, Area Under Curve, geeft het gebied onder de lijn weer. Hoe hoger dit getal is, hoe beter de prestatie van het model is.
De lijn van ons model begeeft zich boven de lijn, wat goed is. Echter dit kan beter. Er zijn meerdere richtingen die verkend kunnen worden om prestaties te verbeteren. Hieronder vallen:
- Feature engineering: toevoegen van nieuwe kennis
- Hyperparameter tuning: settings van het model aanpassen
- Type model veranderen
Als we bijvoorbeeld in plaats van logistic regression uit package sklearn het classification algoritme vanuit package XGBoost gebruiken zien we het volgende:
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
probabilities = model.predict_proba(X_test)
plot_auc(y_test, probabilities)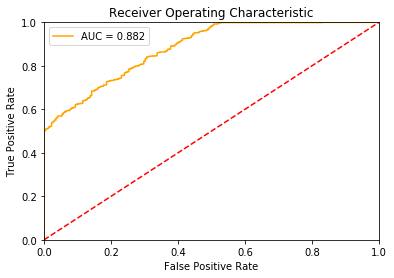
Hiermee is de performance aanzienlijk verbeterd, AUC is verhoogd van 0.587 naar 0.882. De prestatie van een dergelijk niveau is bruikbaar en kan goed gebruikt worden om waarde toe te voegen in het productiebedrijf door vooraf te voorspellen welke artikelen risicovoller zijn om te produceren dan andere.
Tot slot
In deze tutorial hebben we de dataset van een productiebedrijf onder de loep genomen en er een waardevol voorspellingsmodel op gemaakt. Dit hebben we gedaan door de dataset te importeren en, de data te verkennen en op te schonen. Zo zijn rijen met niet betrouwbare waarden verwijderd. Vervolgens hebben we met feature engineering nieuwe kolommen toegevoegd die voorspellende waarde hebben. De dataset is opgesplitst in train en testdata en gebalanceerd. We hebben een model gemaakt en hebben hiervan verschillende prestatieindicatoren bekeken en beoordeeld. Tot slot hebben we door een aanpassing te doen de performance van het model aanzienlijk verbeterd.
Na het doorlopen van deze tutorial heb je nu de vaardigheden om een machine learning classificatiemodel in Python te maken. Je weet nu waar je op moet letten en welke mogelijkheden je hebt om verbeteringen aan te brengen waarmee je model beter gaat presteren.
Wil je nog veel meer leren over de mogelijkheden van Machine Learning in Python en samenwerken met andere Data Scientists en ervaren trainers? Schrijf je dan in voor onze Python Machine Learning Training en vergroot je vaardigheden gecombineerd met mooie voorbeelden en praktijkcases.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.