Starten met Python for Data Science
Python is erg geschikt voor data science, maar hoe leer je Python? In deze blog leggen we je tien essentiële stappen uit. Na het lezen van deze blog zal je je eerste model gemaakt hebben en mag je jezelf een (beginnende) data scientist noemen.
We zullen deze stappen doornemen:
- Installeer Python en Jupyter Notebook
- Start Jupyter Notebook
- Importeer data science packages
- Importeer een dataset
- Dataset verkennen
- Dataset opschonen
- Feature engineering
- Dataset opsplitsen in train en test data
- Machine learning model trainen en beoordelen
- Vervolgstappen
De stappen worden doorlopen via een voorbeeld case. In deze case dient de benodigde tijd om in een magazijn per order alle bestellingen te verzamelen voorspeld te worden.
1. Installeer Python en Jupyter Notebook
Als je met Python wilt gaan werken heb je naast Python zelf ook een programma nodig waarin je code kan schrijven en vervolgens kunt uitvoeren. Hiervoor zijn meerdere oplossingen, maar één van de handigste en meest gebruikte is Jupyter Notebook. Wil je een uitgebreide uitleg over de installatie van Python (voor Windows en Mac), lees dan onze blog "Hoe installeer en gebruik ik Python".
Ga om Python te installeren naar https://www.python.org/downloads/ en download de meest recente versie. Open het gedownloade bestand en vink "Add Python 3.x to PATH" aan. Doorloop de gehele installatie.
Open nadat de Python installatie voltooid is de command prompt (Windows) of terminal (Mac). Voer hier 'pip install jupyter notebook' in en druk op enter. De installatie van Jupyter Notebook wordt gestart, wacht tot dit proces voltooid is. Een uitgebreidere uitleg van hoe je Jupyter Notebook installeert lees je hier.
2. Start Jupyter Notebook
Ga wederom naar de command prompt of terminal, voer 'jupyter notebook' in en druk op enter. Jupyter Notebook zal nu in de browser geopend worden. Navigeer hierin via de mappenstructuur naar een locatie van je voorkeur. Maak een nieuw Notebook door rechtsboven op 'New' te klikken, en klik hier op 'Python 3'.
3. Installeer en importeer packages
Middels het importeren van packages kunnen eenvoudig additionele functionaliteiten toegevoegd worden die niet standaard in Python aanwezig zijn. Denk hiervoor bijvoorbeeld aan Python functies om machine learning algoritmes te kunnen gebruiken.
In de voorbeeld case van deze blog zal gebruik gemaakt worden van de volgende packages:
- Pandas: we zullen pandas gebruiken voor het lezen en bewerken van tabulaire data.
- Matplotlib: we gebruiken hiervan de de module pyplot om grafieken te maken
- Scitkit-learn: we gebruiken van deze module het algoritme LinearRegession, dit is een machine learning model.
3.1 Python package installeren
Om gebruik te kunnen maken van een package dient dit allereerst geïnstalleerd te worden. Doe dit door naar de command prompt of terminal te gaan, voer hier 'pip install [package-name]' in en druk op enter. Hierbij dient package-name vervangen te worden door de naam van het te installeren package.
Installeer de drie benodigde packages op de volgende manier:pip install scikit-learn
pip install pandas
pip install matplotlib
pip install xlrd
Als je een Mac hebt en de packages installeren niet. Installeer dat eerst Homebrew zoals staat omschreven in de post "Hoe installeer ik Python".
3.2 Python package gebruiken
Een package gebruik je door in de code, dus bijvoorbeeld in een Jupyter Notebook, het package te importeren. Dit doe je door bovenaan de code het commando 'import' te gebruiken, gevolgd door de naam van de package die je wilt gebruiken.
import pandas as pd
import matplotlib.pyplot as plt%matplotlib inline
from sklearn.linear_model import LinearRegression
Je ziet dat we op drie verschillende manieren packages installeren:
- Door de notatie 'import pandas as pd', gebruiken we vanaf nu het alias 'pd' voor pandas. Dit is handig omdat je dit vaak moet intypen en 'pd' is uiteraard korter dan 'pandas'.
- Van het package matplotlib importeren we alleen de module pyplot.
- Van het package sklearn (de notatie voor scikit) willen we alleen alleen het lineaire model 'LinearRegression' importeren.
Naast de genoemde packages zijn er nog vele anderen beschikbaar. Bekijk voor meer details over packages de blog waarin we een volledig overzicht presenteren van de meest gebruikte Python packages voor Data Science.
4. Importeer de dataset
Voor deze voorbeeldcase wordt als dataset gebruik gemaakt van een Excel bestand (lees ook: Excel vs Python). Met het inmiddels geïmporteerde package pandas kan dit bestand uitgelezen en gebruikt worden.
Download allereerst de dataset en sla dit bestand op in dezelfde map als waar het Jupyter Notebook is aangemaakt.
Gebruik dan de volgende code om het bestand uit te lezen en de inhoud op te slaan onder de naam df (df staat voor dataframe). Voer de code uit met het commando CTRL + Enter of door op de run knop te klikken.
df = pd.read_excel('dataset_order_picking.xlsx')
Na het runnen van deze code is de dataset succesvol geïmporteerd. Voer om een indruk te krijgen van de inhoud de volgende code uit. Hiermee worden de bovenste 5 rijen weergegeven.df.head()

5. Dataset verkennen
In de vorige stap is de dataset geïmporteerd en is een eerste indruk gegeven van de inhoud. Om een beter idee te krijgen van deze inhoud en de mogelijke onderlinge relaties tussen gegevens wordt in dit voorbeeld gebruik gemaakt van een pairplot. Dit is een standaard functie vanuit het package seaborn. Hiermee wordt voor alle kolommen met numerieke waarden een scatter plot gemaakt. Daarnaast wordt voor elke kolom met numerieke waarden een histogram geplot.
Installeer seaborn via Terminal of command line (pip install seaborn) en voer onderstaande code uit om de pairplot weer te geven.
import seaborn as sns
sns.pairplot(df, kind='reg')
plt.show()
Op de neerwaartse diagonaal zijn de histogrammen te zien, de overige subplots zijn de scatterplots tussen de verschillende variabelen. Hierin is ook een trendlijn geplot.
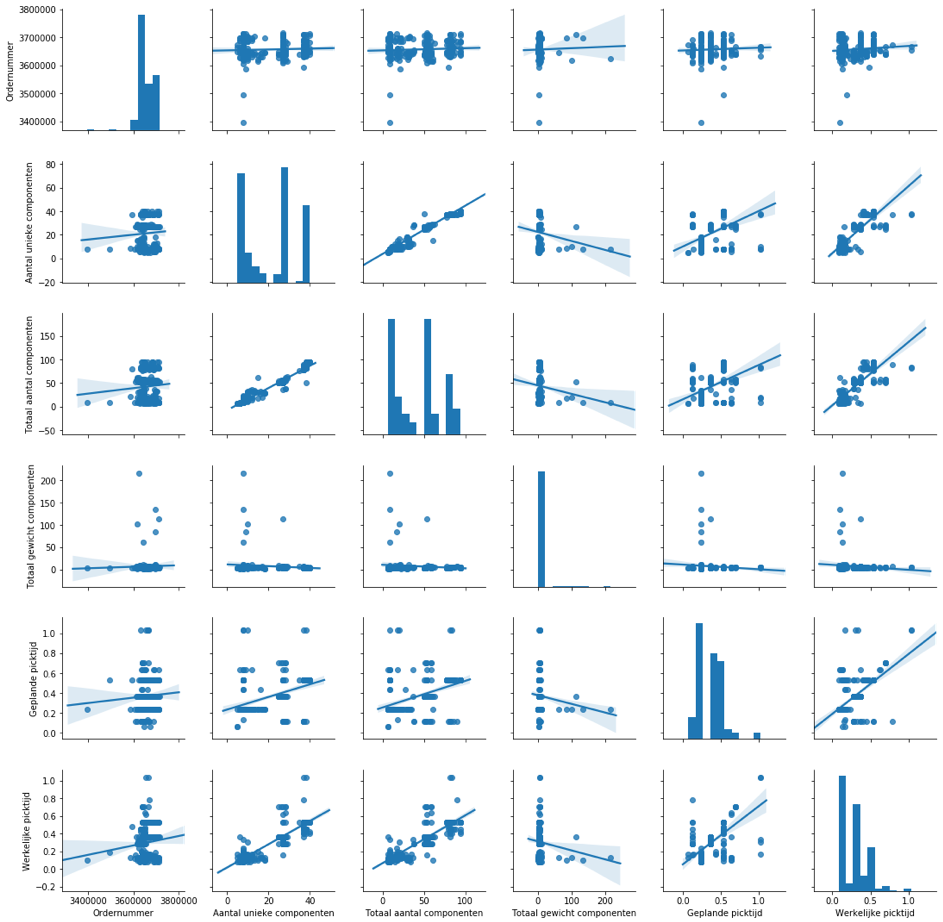
Er is nu bijvoorbeeld op te merken dat hoe hoger het aantal unieke componenten is, hoe langer de werkelijke picktijd is.
Naast kolommen met numerieke waarden bevat de dataset ook een kolom met categoriale data, zoals de productgroep. Om de relatie tussen een dergelijke kolom en de te voorspellen kolom zichtbaar te maken kan gebruik gemaakt worden van bijvoorbeeld een Python boxplot. Voer onderstaande code uit om de boxplot te plotten.fig, ax = plt.subplots(figsize=(15,5))
sns.boxplot(data=df, ax=ax, x='Productgroep', y='Werkelijke picktijd')
ax.set_xticklabels(ax.get_xticklabels(),rotation='vertical')
plt.show()
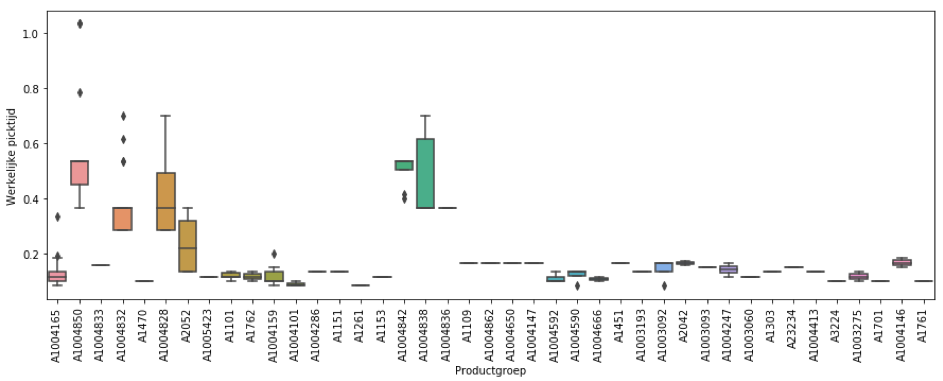
De bloxplot geeft het inzicht dat er duidelijke verschillen aanwezig zijn tussen de diverse productgroepen.
Er zijn tal van andere en additionele methoden om de dataset te verkennen. Het is goed om hiermee te experimenteren.
6 Dataset opschonen
Datasets zijn zelden kant en klaar voor gebruik. Veelal zal je de data eerst moeten opschonen. Denk hiervoor bijvoorbeeld aan missende of onjuiste waarden. Om de dataset zo goed mogelijk overeen te laten
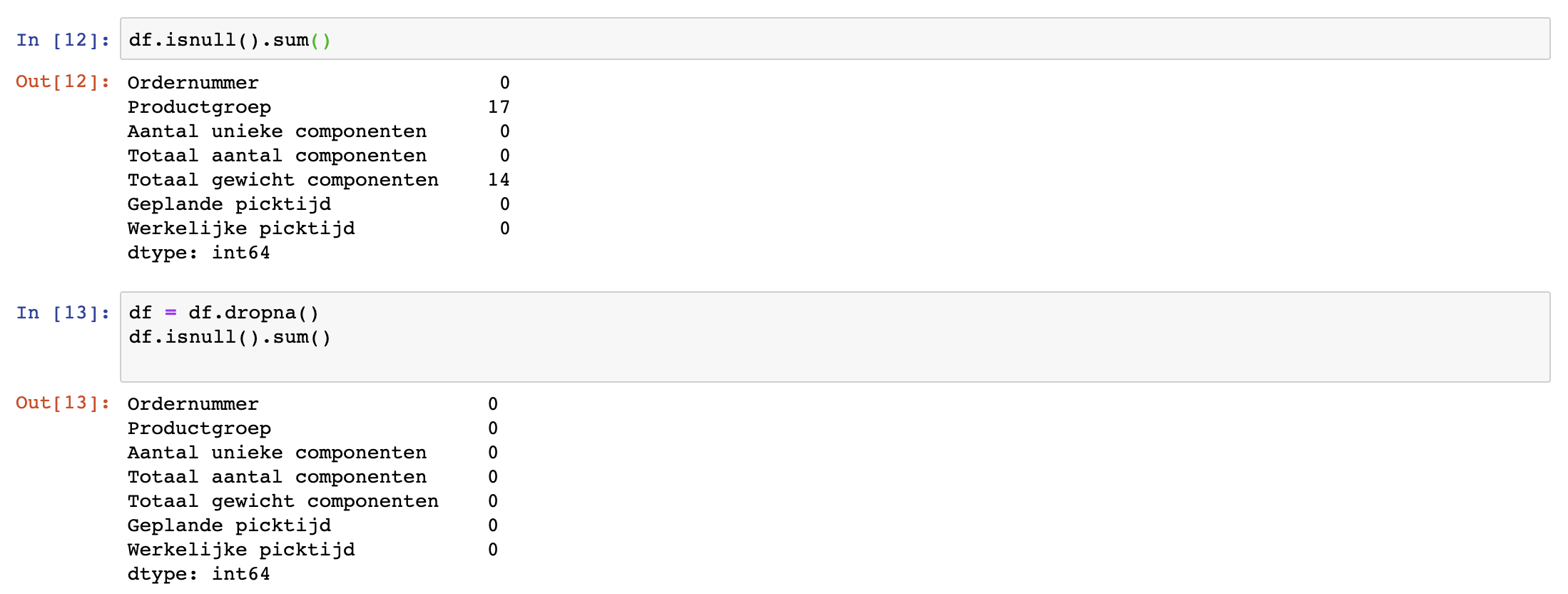
Zoals te zien was bij het importeren van de dataset bevatten enkele kolommen lege waarden (te herkennen aan 'NaN'). Dit kan problematisch zijn. Daarom willen we inzichtelijk hebben hoe vaak dit probleem voorkomt. Met onderstaande code wordt duidelijk hoeveel lege waarden elke kolom bevat.
df.isnull().sum()
Er zijn meerdere manieren te bedenken om met lege waarden om te gaan. Zo kan er bijvoorbeeld het gemiddelde van alle waarden ingevuld worden. In dit voorbeeld zullen de rijen van lege waarden verwijderd worden.df = df.dropna()
df.isnull().sum()
De output laat nu zien dat er geen missende data meer is.
7. Feature engineering
Om het meeste uit een dataset te halen kan het handig zijn om met specifieke kennis nieuwe kolommen (features) toe te voegen. Immers, hoe sterker de verbanden tussen de voorspellende kolommen en de beoogde uitkomst is, hoe beter het model zal kunnen presteren.
Ter illustratie zullen extra kolommen met numerieke waarden toegevoegd worden gebaseerd op de categoriale kolom productgroep. Deze kolom is zelf namelijk niet direct bruikbaar omdat voor een regressiemodel alleen numerieke waarden gebruikt kunnen worden.
Met onderstaande code zal voor elke unieke waarde uit de kolom productgroep een nieuwe kolom aangemaakt worden met in elke cel twee mogelijke waarden: 0 of 1.
df = pd.get_dummies(df, columns=['Productgroep'])

Als dan een rij een bepaalde productgroep waarde heeft, zal de bijbehorende nieuwe kolom een waarde van 1 hebben. De overige nieuwe kolommen hebben een waarde gelijk aan 0. Hiermee is op numerieke wijze het verband gelegd tussen de verschillende productgroepen.
Er zijn tal van andere richtingen te bedenken om met specifieke kennis meer waarde toevoegende features te implementeren. Denk voor deze case bijvoorbeeld aan het toevoegen van de volgende features:
- De totale onderlinge afstand van alle te picken componenten per order
- In hoeveel verschillende stellingen de componenten liggen
- Of er voor deze order componenten gepickt moeten worden waarvan al bekend is dat dit significant langer duurt dan gemiddeld
8. Dataset opsplitsen in train- en testdata
Machine Learning is het uitrusten van computers met 'ervaring' zodat ze patronen kunnen vinden, leren en voorspellen op data die ze nog niet eerder gezien hebben. Het maakt gebruik van algoritmes om op basis van historische data te kunnen voorspellen.
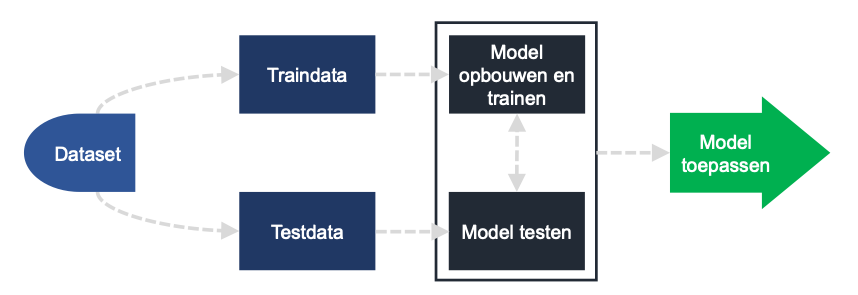
Dit doe je in drie stappen:
- Een model maken dat je traint op basis van een deel van de data (traindata)
- Het model evalueren door een voorspelling te maken voor de overige data (testdata)
- De voorspelling met de werkelijke data vergelijken
Bij het aanmaken van een model is het essentieel om te beoordelen hoe het model presteert op nieuwe data. Als het model goed presteert op de data waarmee het getraind is, maar belabberd op nieuwe data, dan is het model nog steeds waardeloos. Dit noemen we 'overfitting'.
Idealiter wil je met zo min mogelijk data een zo goed mogelijke voorspelling kunnen doen. Daarom wordt de dataset opgesplitst in train- en testdata. Met traindata wordt het model getraind, de testdata wordt als nieuwe data gebruikt ter validatie van het model.
Allereerst maken we met onderstaande code een selectie van output en feature kolommen.
y = df['Werkelijke picktijd']
X = df.drop(['Ordernummer', 'Geplande picktijd', 'Werkelijke picktijd'], axis=1)
Hierbij is y de kolom met waarden die voorspeld moeten gaan worden. X bevat de feature kolommen. Er is hierbij gekozen om kolommen die niet gebruikt gaan worden te verwijderen in plaats van de te gebruiken kolommen expliciet te selecteren. Dit vanwege de in de stap feature engineering toegevoegde nieuwe kolommen.
Nu kan de data opgesplitst worden in train en test data.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
In deze functie geeft parameter test_size aan dat 20% testdata geselecteerd zal worden. Parameter random_state is een vrij te kiezen nummer wat resulteert in een willekeurige toewijzing van train- en testdata, de toewijzing zal echter wel elke keer hetzelfde zijn zolang je de waarde van 'random_state' niet varieert.
9. Machine learning model trainen en beoordelen
Machine learning richt zich veelal op één van de twee toepassingsgebieden: (1) classificatievraagstukken, waarbij een categorie voorspeld moet worden, en (2) regressievraagstukken, waarbij een numerieke waarde voorspeld moet worden. Beide zijn voorbeelden van supervised learning.
Nu de dataset opgesplitst is kan het model getraind worden. We kiezen hier voor een regressiemodel omdat we een numerieke waarde willen voorspellen. Met onderstaande code wordt eerst een model gedefinieerd, waarna dit op basis van de traindata getraind wordt.
model = LinearRegression()model.fit(X_train, y_train)
Zodra het model getraind is kan het gebruikt worden om uitkomsten te voorspellen. De volgende code geeft de uitkomsten voor zowel de train als test input data, voorspeld door het aangemaakte model.
y_train_score = model.predict(X_train)y_test_score = model.predict(X_test)
Om de prestaties van het model te kwantificeren zijn meerdere methoden toe te passen. Dit doe je door de voorspeelde waarde te vergelijken met de werkelijke waarde. Dit kan op meerdere manieren, ter illustratie zullen twee veelgebruikte metrics berekend worden: (1) de root mean square error (RSME) en (2) de determinatiecoëfficiënt (R²).
print('Train data:')
print('RSME = ' + str(sqrt(mean_squared_error(y_train, y_train_score))))
print('R^2 = ' + str(r2_score(y_train, y_train_score)))
print('Test data:')
print('RSME = ' + str(sqrt(mean_squared_error(y_test, y_test_score))))
print('R^2 = ' + str(r2_score(y_test, y_test_score)))
Voor zowel de train- als testdata zijn de metrics getoond. Het valt op dat de waarden van deze metrics voor train- en testdata dezelfde orde van grootte hebben. Gebaseerd hierop kan geconcludeerd worden dat het model bruikbare waarde heeft voor nieuwe data.
10. Vervolgstappen
Met deze case is van begin tot eind het data science proces doorlopen om met Python in Jupyter Notebook een machine learning model toe te passen op een dataset.
Voor de leesbaarheid en het begrip is dit erg high level gedaan. Bij elk van de stappen zijn meer mogelijkheden denkbaar en kan verdere verdieping nuttig zijn.
Door creatief na te denken en het model stap voor stap uit te bouwen zal je kennis op gebied van data science in Python groeien.
Denk hiervoor bijvoorbeeld aan de volgende richtingen:
- Slimme methoden toepassen ter omgang met missende data
- Nieuwe kolommen toevoegen (feature engineering) vanuit additionele databronnen
- Hyperparameter tuning van het model
- Verschillende modellen vergelijken
- Het model in een productieomgeving toepassen
Wil je nog veel meer leren over Python en Data Science? Schrijf je dan in voor onze Python cursus voor data science, onze machine learning training, of voor onze data science opleiding en leer met vertrouwen te programmeren en analyseren in Python. Nadat je een van onze trainingen hebt gevolgd kun je zelfstandig verder aan de slag.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.