In dit blog gaan we in hoe je grote API calls opdeelt in batches met Python. Dit kan noodzakelijk zijn als je grote hoeveelheden data op wilt halen. Python is een programmeertaal waarmee je makkelijk interactie kunt hebben met APIs. Python wordt veel gebruikt door data scientists in data science vraagstukken en kent enorm veel toepassingen.
In dit blog
In dit blog behandelen we de volgende onderwerpen:
- Wat is een API
- Hoe haal ik in batches data op uit een API met Python?
- Samenvatting m.b.t. batches & APIs
Wat is een API?
API staat voor Application Programming Interface. Dit is een gestandaardiseerde en gestructureerde manier om met andere applicaties interactie te hebben.
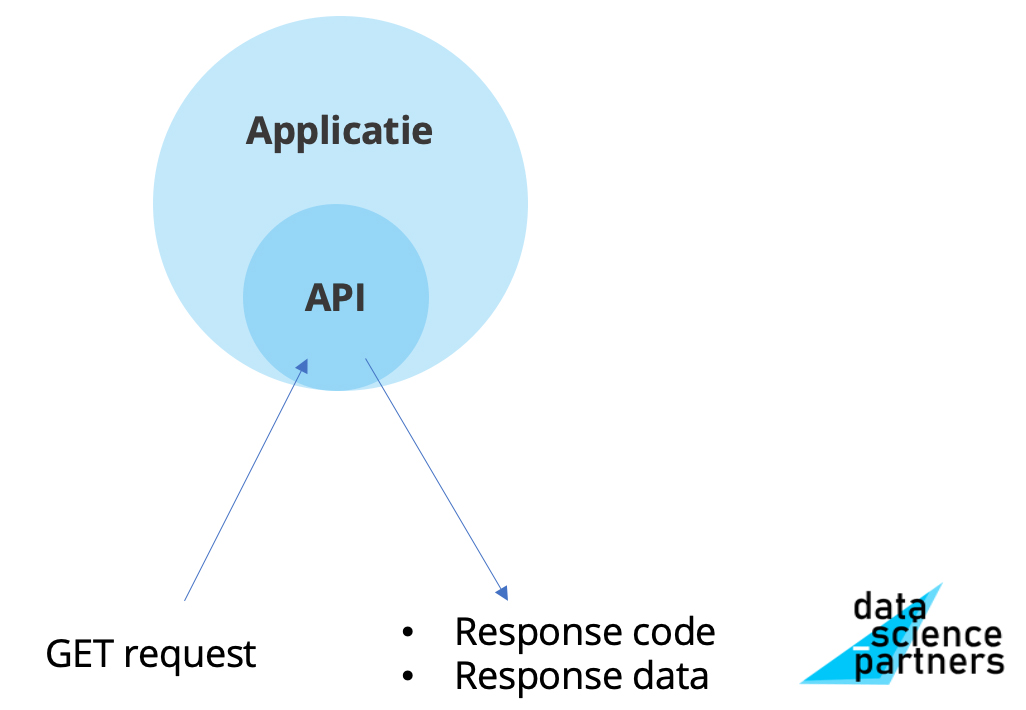
In onderstaande afbeelding zie je simpel visueel weergegeven hoe een API werkt als je data ophaalt met een GET request.
Om aan de slag te gaan met APIs kun je ook onze andere blogs hierover raadplegen.
Hoe haal ik in batches data op uit een API?
In sommige gevallen is het de hoeveelheid data die je op kunt halen beperkt. Bij het CBS (Centraal Bureau voor de Statistiek) API is dit bijvoorbeeld beperkt op 10.000 rijen.
Dat zie je in onderstaand voorbeeld:
import requests
api_url = 'https://opendata.cbs.nl/ODataFeed/odata/83625NED/TypedDataSet'
headers = {
'accept': 'application/json'
}
response = requests.get(api_url, headers=headers)
len(response.json()['value'])
10000We krijgen hier "maar" 10.000 rijen terug.
Stap 1: Het aantal datapunten opvragen
In zo'n geval kun je meestal wel het totale aantal datapunten opvragen.
Dan weet je wat je hebt en wat je mist.
Je ziet hoe je dat met de CBS API doet in het volgende voorbeeld.
NB: per API kan dit verschillen, kijk hiervoor altijd in de documentatie van de API.
import requests
api_url = 'https://opendata.cbs.nl/ODataFeed/odata/83625NED/TypedDataSet/$count'
headers = {
'accept': 'application/json'
}
response = requests.get(api_url)
count_rows = response.json()
print(count_rows)
19240Je ziet dat het aantal groter is dan 10.000.
Stap 2: Opdelen in batches
We kunnen per GET call 10.000 rijen ophalen.
Hierdoor kunnen we de opdracht in batches opdelen, om toch alle data te verkrijgen.
In onderstaande code berekenen we het aantal benodigde batches:
import math
PAGE_SIZE = 10000
pages = math.ceil(count_rows / PAGE_SIZE)
print(pages)
2Stap 3: Ophalen in batches
Nu we weten hoeveel batches er nodig zijn, kunnen we de data op gaan halen.
In onderstaande code doen we dit, met een [for loop](https://datasciencepartners.nl/python-for-loop/ "for loop").
import pandas as pd
api_url = 'https://opendata.cbs.nl/ODataFeed/odata/83625NED/TypedDataSet'
headers = {
'accept': 'application/json'
}
df = pd.DataFrame()
for page_number in range(pages):
params = {
'$skip': page_number * PAGE_SIZE,
}
response = requests.get(api_url, headers=headers, params=params)
json_data = response.json()['value']
_df = pd.DataFrame(json_data)
df = pd.concat([df, _df], ignore_index=True)
df
| ID | RegioS | Perioden | GemiddeldeVerkoopprijs_1 | |
|---|---|---|---|---|
| 0 | 0 | NL01 | 1995JJ00 | 93750.0 |
| 1 | 1 | NL01 | 1996JJ00 | 102607.0 |
| 2 | 2 | NL01 | 1997JJ00 | 113163.0 |
| 3 | 3 | NL01 | 1998JJ00 | 124540.0 |
| 4 | 4 | NL01 | 1999JJ00 | 144778.0 |
| ... | ... | ... | ... | ... |
| 19235 | 19235 | GM0193 | 2016JJ00 | 228479.0 |
| 19236 | 19236 | GM0193 | 2017JJ00 | 245803.0 |
| 19237 | 19237 | GM0193 | 2018JJ00 | 279684.0 |
| 19238 | 19238 | GM0193 | 2019JJ00 | 293098.0 |
| 19239 | 19239 | GM0193 | 2020JJ00 | 315874.0 |
19240 rows × 4 columns
Je ziet dat we nu alle data hebben!
Om te onthouden
- Soms wil je grotere hoeveelheden data ophalen dan direct mogelijk is met een API.
- Dan kun je de data batchgewijs in meerdere herhalingen ophalen.
- Kijk altijd in de documentatie van de API die je gebruikt hoe je dit doet. Het verschilt per API.
Wil je nog veel meer leren over met mogelijkheden met Python voor Data Science? Schrijf je dan in voor onze Python cursus voor data science, onze machine learning training, onze data science opleiding of onze data science bootcamp en leer met vertrouwen te programmeren en analyseren in Python. Nadat je een van onze trainingen hebt gevolgd kun je zelfstandig verder aan de slag. Je kunt ook altijd even contact opnemen als je een vraag hebt. Bij al deze trainingen is het mogelijk een zelfstudie add-on te selecteren waarin je meer leert over werken met APIs vanuit Python

Download één van onze opleidingsbrochures voor meer informatie

Rik is data scientist en marketeer bij Data Science Partners. Vanuit zijn achtergrond op de Technische Universiteit Eindhoven heeft hij veel affiniteit met data. Na zijn studie heeft hij als consultant altijd met data gewerkt en tevens ervaring opgedaan in het geven van trainingen.