Met Roseman Labs software kan (gevoelige) data vanuit verschillende partijen op een veilige manier worden samengevoegd. Waarna de samengevoegde data bijvoorbeeld bewerkt en geanalyseerd kan worden. En dit zonder dat een partij toegang heeft tot de data van een andere partij. Dit biedt een oplossing wanneer gevoelige data samengevoegd zou moeten worden om waardevolle inzichten te verkrijgen, maar dit vanwege gevoeligheid niet kan of niet gewenst is.
1. Waarom zouden we data delen, een voorbeeld uit de zorg
Data vanuit verschillende partijen samenbrengen kan tot nieuwe waardevolle inzichten leiden. Om dit te begrijpen kijken we naar een voorbeeld in de zorg. Daarbij de situatie van meerdere ziekenhuizen die allen patiënten behandelen met een bepaalde aandoening:
- Elk van de ziekenhuizen heeft slechts de data van haar eigen patiënten, en heeft geen toegang tot de data van andere ziekenhuizen.
- De data die elk ziekenhuis afzonderlijk heeft is in dit voorbeeld te beperkt om conclusies uit te trekken of een bepaalde behandeling effect heeft.
- Wanneer de data vanuit de verschillende ziekenhuizen samengebracht wordt, is deze dataset statistisch gezien sterker.
- Hierdoor kunnen uit de gezamenlijke dataset wellicht wel conclusies getrokken worden over het effect van een bepaalde behandeling.
- Dit kan bijdragen aan verbetering van de zorg.
Bovenstaand voorbeeld is slechts 1 van vele mogelijke toepassingen van het samenvoegen van data. In dit voorbeeld combineerden we vergelijkbare data van verschillende patiënten vanuit meerdere ziekenhuizen. Je kunt ook denken aan het verreiken van data van dezelfde patiënt, vanuit verschillende bronnen. Bijvoorbeeld door patiëntdata van de huisarts te combineren met die van het ziekenhuis. Dit soort voorbeelden beperken zich uiteraard niet tot de zorg. En zijn net zo goed mogelijk binnen andere sectoren zoals de publieke sector, financiële dienstverlening, of de energiesector.
2. Uitdagingen bij het delen van data
Wanneer data persoonsgegevens bevatten is de Algemene Verordening Gegevensbescherming (AVG) wetgeving van toepassing. Deze wetgeving legt strikte richtlijnen vast met betrekking tot het delen van persoonsgegevens. Volgens de AVG mogen persoonsgegevens alleen worden gedeeld indien er een rechtmatige basis is. Zoals bijvoorbeeld door uitdrukkelijke toestemming van de betrokkenen. Daarnaast vereist de AVG dat de partijen die persoonsgegevens delen, passende technische en organisatorische maatregelen treffen. Dit om een hoog niveau van gegevensbescherming te waarborgen. Hierdoor mogen data die persoonsgegevens bevatten dus niet zomaar gedeeld worden tussen partijen.
Naast dat de AVG van toepassing kan zijn, wil een partij wellicht ook niet zomaar data delen met een andere partij. Bijvoorbeeld omdat de data bedrijfsgevoelige informatie bevat. Er zijn dus meerdere redenen waarom data delen met een andere partij niet gewenst of mogelijk zijn. Maar dat er wel meerwaarde bestaat van het samenbrengen en analyseren van data vanuit verschillende partijen.
3. Oplossing voor uitdagingen bij het delen van data: Roseman Labs
Roseman Labs biedt een oplossing met hun software en een eigen package voor programmeertaal Python: crandas. Een dergelijke technische oplossing om privacy te verbeteren en/of waarborgen wordt ook wel een privacy enhancing technology (PET) genoemd.
Met haar oplossing maakt Roseman Labs het mogelijk om gevoelige data vanuit verschillende partijen veilig samen te voegen om waardevolle inzichten te ontsluiten.
- Maar dit zonder dat er ergens een gecombineerde dataset opgeslagen wordt.
- En zonder dat iemand van de ene partij de data van een andere partij in kan zien.
Hiervoor gebruikt Roseman Labs een techniek genaamd secure multi-party computation. Op hun website staat een uitgebreide uitleg en een demonstratie, maar in het kort werkt het als volgt:
- Elk van de partijen versleutelt hun data lokaal.
- Als onderdeel hiervan wordt de data in delen opgesplitst.
- Deze versleutelde en opgedeelde data wordt naar verschillende servers geüpload.
- Middels package crandas kan de data virtueel gecombineerd en geanalyseerd worden.
- Zonder dat de data hierbij ontsleuteld dient te worden.
Om dit in de praktijk te ervaren, doorlopen we in de volgende stappen een voorbeeld.
4. Voorbeeld gebruik Roseman Labs software en package crandas
In dit voorbeeld werken we met 3 datasets met gegevens van diabetespatiënten uit verschillende ziekenhuizen. Deze datasets zijn door elk van de ziekenhuizen toegevoegd aan Roseman Labs. Hierdoor kun je als data analist of onderzoeker, als je de juiste rechten hebt, de 3 datasets van de 3 ziekenhuizen wel analyseren en onderzoeken, maar niet inzien. Zo is deze methode te gebruiken als veilige manier om data uit te wisselen.
4.1. Datasets uploaden
In dit voorbeeld maken we gebruik van een demo-omgeving van Roseman Labs. En werken we hierbinnen in een Jupyter Labs omgeving met programmeertaal Python. In een productie-omgeving van Roseman Labs kun je uitsluitend met scripts werken die door data holders/controllers zijn goedgekeurd.
In deze demo-omgeving bevinden zich al de 3 datasets met gegevens van diabetespatiënten uit verschillende ziekenhuizen. Allereerst gaan we de datasets uitlezen en uploaden. Daarmee simuleren we de situatie dat elk van de ziekenhuizen een dataset zou hebben geüpload naar Roseman Labs.
Om met datasets te werken vanuit Roseman Labs gebruiken we hun package crandas. Dit is deels gebaseerd op package pandas, het meestgebruikte package om met data in tabelvorm te werken.
4.1.1. Uploaden
In onderstaande code doen we het volgende:
- Importeren package crandas.
- Specificeren de bestandspaden van de datasets.
- Lezen de 3 datasets uit met de read_csv() methode. Dit is erg vergelijkbaar als hoe je met pandas een CSV bestand zou uitlezen.
- Middels het uitlezen worden de datasets geüpload naar Roseman Labs.
- Bewaren van de 3 datasets in variabelen
df_1,df_2endf_3.
# Import package crandas
import crandas as cd
# Set dataset filepaths
filepath_dataset_1 = "../../data/diabetes_data/diabetes_dummy_1.csv"
filepath_dataset_2 = "../../data/diabetes_data/diabetes_dummy_2.csv"
filepath_dataset_3 = "../../data/diabetes_data/diabetes_dummy_3.csv"
# Read datasets with crandas
df_1 = cd.read_csv(filepath_dataset_1, name="dataset_1", auto_bounds=True)
df_2 = cd.read_csv(filepath_dataset_2, name="dataset_2", auto_bounds=True)
df_3 = cd.read_csv(filepath_dataset_3, name="dataset_3", auto_bounds=True)
4.1.2. Handles
Elke naar Roseman Labs geüploade dataset heeft een handle. Dat is een referentie naar de dataset die bestaat uit een hexadecimale string van 64 tekens. We verkrijgen deze handles in dit voorbeeld als volgt:
- Verkrijgen de handles met attribuut
handle, voor iedere dataset. - Bewaren deze handles in variabelen.
- Tonen één handle, als voorbeeld.
# Get dataset handles
handle_df_1 = _df_1.handle
handle_df_2 = _df_2.handle
handle_df_3 = _df_3.handle
handle_df_1
Output:
'BF4967AF13A64A1754BE528A991EBFF736F7BDADC3D01AE9D40DA91CC8952423'We hebben nu een praktijksituatie nagebootst. Dit waarin elk van de 3 ziekenhuizen een dataset zou hebben geüpload naar Roseman labs. En waarbij we van iedere dataset in Roseman labs een bekende handle heeft. Een referentie naar de dataset. Die we moeten gebruiken om de dataset in Roseman Labs te benaderen voor gebruik.
4.2. Datasets benaderen
Roseman Labs is ontworpen om datasets te beschermen. Daarom kun je een datasets niet zomaar uitlezen zoals je bijvoorbeeld met package pandas een CSV-bestand zou uitlezen. In plaats daarvan kun je met Roseman Labs vanuit package crandas een dataset benaderen met functie get_table(). Je hebt dan toegang tot de data, maar kunt de data slechts zeer beperkt inzien.
In onderstaande code lezen we de 3 datasets uit met behulp van de inmiddels bekende handles. En we bekijken de output van één dataset.
# Access datasets
df_1 = cd.get_table(handle_df_1)
df_2 = cd.get_table(handle_df_2)
df_3 = cd.get_table(handle_df_3)
df_1
Output:
Handle: BF4967AF13A64A1754BE528A991EBFF736F7BDADC3D01AE9D40DA91CC8952423
Size: 100 rows x 18 columns
CIndex([Col("Patientnr", "i", 1), Col("M/V", "i", 1), Col("Leeftijd", "i", 1), Col("patient_sims", "i", 1), Col("zorgprofiel", "i", 1), Col("Hoofdbehandelaar", "i", 1), Col("Podotherapeut huisbezoek", "i", 1), Col("Pedicure huisbezoek", "i", 1), Col("DM Type", "i", 1), Col("Tekenen van infectie", "i", 1), Col("Ulcus/amputatie", "i", 1), Col("Inactieve charcot-voet", "i", 1), Col("Nierfalen/Dialyse", "i", 1), Col("Pulsaties links", "i", 1), Col("Pulsaties rechts", "i", 1), Col("Doppler links", "i", 1), Col("Doppler rechts", "i", 1), Col("Huidig schoeisel", "i", 1)])We zien nu enkele details van de dataset: de handle, de vorm, en informatie over de kolommen. Maar niet de werkelijke data; die is beschermd.
In onderstaande code geven we elke dataset een naam, met attribuut name. Dit gebruiken we later in dit voorbeeld.
# Set dataset names
df_1.name = "dataset_1"
df_2.name = "dataset_2"
df_3.name = "dataset_3"
df_1.name
Output:
'dataset_1'Te zien is dat de datasets een naam hebben gekregen.
4.3. Datasets verkennen
Vanuit package pandas bestaan er diverse manieren om datasets te verkennen. Deze zijn deels ook te gebruiken vanuit package crandas. Crandas heeft echter geen methoden geïmplementeerd waarmee een dataset volledig of deels te zien is. Dit voor afscherming en dus beveiliging van de data.
4.3.1. Celwaarden verkennen
Bijvoorbeeld de head() methode die we in pandas wel kennen, is in crandas niet beschikbaar. Dit omdat je met deze methode de cellen van de eerste 5 rijen te zien krijgt. Crandas zorgt voor afscherming van de data. Daarom kunnen we deze methode niet gebruiken. Zie onderstaand voorbeeld.
# Try to show top row values
df_1.head()
Output:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In [3], line 1
----> 1 df_1.head()
AttributeError: 'CDataFrame' object has no attribute 'head'We krijgen een AttributeError doordat methode head() niet bestaat. Hetzelfde is van toepassing bij het gebruik van iloc[]. Dit is een methode waarmee we in package pandas een selectie van waarden uit rijen en kolommen kunnen maken. Zie onderstaand voorbeeld.
# Try to show top row values
df_1.iloc[:5]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In [4], line 1
----> 1 df_1.iloc[:5]
AttributeError: 'CDataFrame' object has no attribute 'iloc'Ook hier krijgen we een AttributeError terug als resultaat.
4.3.2. Kolomnamen verkennen
Wel kunnen we bijvoorbeeld gebruik maken van het attribuut columns. Dit geeft ons een overzicht van alle kolomnamen in een dataset. Net als hoe het in pandas werkt. Zie onderstaand voorbeeld.
# Show dataset columns
list(df_1.columns)
Output:
['Patientnr',
'M/V',
'Leeftijd',
'patient_sims',
'zorgprofiel',
'Hoofdbehandelaar',
'Podotherapeut huisbezoek',
'Pedicure huisbezoek',
'DM Type',
'Tekenen van infectie',
'Ulcus/amputatie',
'Inactieve charcot-voet',
'Nierfalen/Dialyse',
'Pulsaties links',
'Pulsaties rechts',
'Doppler links',
'Doppler rechts',
'Huidig schoeisel']4.3.3. Aantal rijen en kolommen van datasets
Met attribuut shape verkrijgen we het aantal rijen en kolommen van een dataset. Dit werkt hetzelfde als in pandas. Zie onderstaand voorbeeld. Daarin gebruiken we een for-loop om van de 3 datasets de naam en shape te printen.
# Print dataset names and shape
for _df in [df_1, df_2, df_3]:
print(f"{_df.name}: {_df.shape}")
Output:
dataset_1: (100, 18)
dataset_2: (100, 18)
dataset_3: (100, 18)Iedere dataset bestaat uit 100 rijen en 18 kolommen.
4.3.4. Statistische samenvatting van dataset
Ook is methode describe() te gebruiken in crandas. Net als hoe het in pandas werkt, geeft het je een statistische samenvatting van de kolommen. Zie onderstaand voorbeeld.
# Describe dataset
df_1.describe()
Output:| Patientnr | M/V | Leeftijd | patient_sims | zorgprofiel | Hoofdbehandelaar | Podotherapeut huisbezoek | Pedicure huisbezoek | DM Type | Tekenen van infectie | Ulcus/amputatie | Inactieve charcot-voet | Nierfalen/Dialyse | Pulsaties links | Pulsaties rechts | Doppler links | Doppler rechts | Huidig schoeisel | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| type | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer | integer |
| count | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| mean | 52,729 | 1 | 51 | 1 | 2 | 1 | 1 | 2 | 1.5 | 1.04 | 0.94 | 1.04 | 1.03 | 1.01 | 0.99 | 2 | 2 | 4 |
| std | 30805.18 | 0.828775 | 26.88827 | 1.12002 | 1.424001 | 1.201682 | 1.098943 | 1.082972 | 0.502519 | 0.8278 | 0.763035 | 0.790346 | 0.822106 | 0.797661 | 0.834787 | 1.474737 | 1.335566 | 2.775706 |
| min | 1075 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| max | 99456 | 2 | 100 | 3 | 4 | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 4 | 4 | 8 |
4.4. Kolommen toevoegen
Met methode assign() kunnen we in crandas een kolom toevoegen. Net als hoe het in pandas werkt.
Zie onderstaand voorbeeld. Hierbij betekent bijvoorbeeld source=df_1.name dat er een nieuwe kolom met naam "source" wordt aangemaakt. Die de waarde krijgt van de naam van het dataframe waar we naar verwijzen. Hiermee bevat ieder van de 3 datasets een kolom "source", met als waarden de naam van de dataset. Zie onderstaand voorbeeld.
# Add source column to datasets with dataset name
df_1 = df_1.assign(source=df_1.name)
df_2 = df_2.assign(source=df_2.name)
df_3 = df_3.assign(source=df_3.name)Door naar de lijst met kolommnamen te kijken controleren we of de nieuwe kolom "source" is toegevoegd. Zie onderstaand voorbeeld.
# Show columns in dataset
list(df_1.columns)
Output:
['Patientnr',
'M/V',
'Leeftijd',
'patient_sims',
'zorgprofiel',
'Hoofdbehandelaar',
'Podotherapeut huisbezoek',
'Pedicure huisbezoek',
'DM Type',
'Tekenen van infectie',
'Ulcus/amputatie',
'Inactieve charcot-voet',
'Nierfalen/Dialyse',
'Pulsaties links',
'Pulsaties rechts',
'Doppler links',
'Doppler rechts',
'Huidig schoeisel',
'source']We zien dat de kolom met naam "source" nu aanwezig is.
In dit voorbeeld hebben we simpelweg een kolom met daarin de naam van een dataset toegevoegd. We hadden bijvoorbeeld ook een kolom met waarden op basis van een berekening toe kunnen voegen.
4.5. Samenvoegen van datasets
Ondanks dat we datasets niet direct in kunnen zien, kunnen we met crandas wel datasets samenvoegen. Daarbij zijn er vergelijkbare mogelijkheden als in pandas. Dit met methoden merge() en concat().
In dit voorbeeld hebben de 3 datasets dezelfde kolomstructuur. We gaan de rijen van de 3 datasets samenvoegen in 1 gecombineerde dataset. Hiervoor gebruiken we de concat() methode. Zie onderstaand voorbeeld. We bewaren de gecombineerde dataset in de variabele met naam df_combined.
Hierbij combineren we 3 maal 100 rijen, uit 19 kolommen. De gecombineerde dataset zou dan 300 rijen en 19 kolommen moeten bevatten. Dit controleren we met het shape attribuut.
# Combine datasets
df_combined = cd.concat(
tables_=[df_1, df_2, df_3],
ignore_index=True,
)
df_combined.shape
Output:
(300, 19)We zien dat de gecombineerde dataset de vorm heeft zoals we verwacht hadden.
4.6. Analyseren van datasets
Package crandas biedt allerlei mogelijkheden om data te analyseren en om statistische tests uit te voeren. Bijvoorbeeld een lineaire regressie en logistische regressie zijn mogelijk.
4.6.1. Selecteren en rekenen
Crandas schermt de data uit de datasets af. Het stelt ons wel in staat om te filteren en zo specifieke selecties te maken. Ook stelt het ons in staat om berekeningen uit te voeren op numerieke kolommen. Bijvoorbeeld met de mean() methode. Daarmee bereken je het gemiddelde van waarden in een kolom.
In onderstaand voorbeeld doen we het volgende:
- In de gecombineerde dataset maken we specifieke selecties op basis van kolom
"source". - Voor iedere selectie berekenen we de gemiddelde leeftijd uit kolom
"Leeftijd"met de mean() methode. - We printen de resultaten.
# Calculate mean age by data source
mean_age_df_1 = df_combined[df_combined["source"] == "dataset_1"]["Leeftijd"].mean()
mean_age_df_2 = df_combined[df_combined["source"] == "dataset_2"]["Leeftijd"].mean()
mean_age_df_3 = df_combined[df_combined["source"] == "dataset_3"]["Leeftijd"].mean()
print(f"Mean age dataset 1: {mean_age_df_1}")
print(f"Mean age dataset 2: {mean_age_df_2}")
print(f"Mean age dataset 3: {mean_age_df_3}")
Output:
Mean age dataset 1: 50.53
Mean age dataset 2: 56.69
Mean age dataset 3: 53.73We zien nu per selectie de gemiddelde leeftijd.
4.6.2. Visualiseren
De berekende uitkomsten kunnen we visualiseren. Dit bijvoorbeeld met een grafiek met package matplotlib. Leer hier meer over matplotlib.
In onderstaand voorbeeld maken we een staafgrafiek met daarin de berekende gemiddelde leeftijden.
# Create chart with mean age values
# Import package matplotlib
import matplotlib.pyplot as plt
# Set variabels
bar_labels = ["Dataset 1", "Dataset 2", "Dataset 3"]
bar_values = [mean_age_df_1, mean_age_df_2, mean_age_df_3]
bar_colors = ["#3498db", "#4682b4", "#5a74a8"]
# Create chart plot object
fig, ax = plt.subplots()
# Plot bars to chart
bars = ax.bar(x=bar_labels, height=bar_values, color=bar_colors, zorder=2)
# Voeg waarden toe bovenop de staven
ax.bar_label(bars, label_type="edge")
# Add grid lines
ax.yaxis.grid(True, linestyle="--", alpha=0.7, color="lightgrey")
# Remove chart border lines
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
# Add title and labels
plt.title("Mean age by data source")
plt.ylabel("Age [years]")
# Show chart
plt.show()
Output: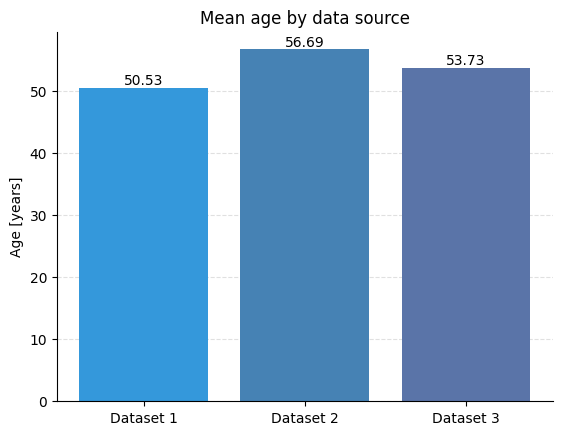
We zien nu een mooie visualisatie van de geanalyseerde data.
4.7. Conclusie gebruik package crandas
Met het Roseman Labs en het package crandas konden we het volgende doen:
- Datasets uitlezen
- Datasets verkennen
- Datasets samenvoegen
- Datasets analyseren
En dit zonder dat we direct toegang hadden tot data uit elk van de datasets. Hierdoor bleef de data veilig afgeschermd, maar konden wel waardevolle inzichten uit de data verkregen worden.
5. Conclusie
Roseman Labs is een oplossing voor het verkrijgen van waardevolle inzichten uit data van meerdere partijen, zonder dat deze data bij een van de partijen werkelijk samengevoegd hoeft te worden. Dat maakt dit een prachtige technologie voor situaties waarbij data delen niet zomaar kan of mag, maar er wel inzichten uit gecombineerde data gewenst zijn. Om met de oplossing van Roseman Labs te werken dien je gebruik te maken van hun package crandas voor programmeertaal Python. Doordat dit package deels is gebaseerd op Python package pandas werkt het erg gemakkelijk en intuïtief voor een data analist die bekend is met Python.
Wil je nog veel meer leren over met mogelijkheden met Python voor Data Science? En zelf de vaardigheden ontwikkelen om met een package als crandas aan de slag te gaan? Schrijf je dan in voor onze Python cursus voor data science, onze machine learning training, onze data science opleiding of onze data science bootcamp en leer met vertrouwen te programmeren en analyseren in Python. Nadat je een van onze trainingen hebt gevolgd kun je zelfstandig verder aan de slag. Je kunt ook altijd even contact opnemen als je een vraag hebt.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.