In veel Data Science vraagstukken ga je als Data Scientist bezig met het maken van modellen die je baseert op Machine Learning algoritmes. Bij supervised machine learning implementaties is het van belang om altijd bewust na te denken over de Bias-Variance Tradeoff.
De afruil tussen bias en variantie is namelijk altijd aanwezig:
- Wie de bias verhoogt binnen een Machine Learning model zal een lagere variantie vinden
- Wie de variantie verhoogt in een Machine Learning model zal een lagere bias vinden
In dit artikel leer je:
- De basis van supervised machine learning
- Wat is bias?
- Wat is variance?
- Wat is de Bias-Variance Tradeoff?
De basis van supervised machine learning
Om de Bias-Variance Tradeoff goed te kunnen begrijpen is het van belang om bij de basis te beginnen. Bij supervised machine learning probeer je een functie (f) zo goed mogelijk te benaderen. Je weet de functie niet, maar wilt deze wel weten zodat je voorspellingen op nieuwe data kunt gaan doen.
Om de functie te benaderen gebruik je training data waarvan je de input data (X) beschikbaar hebt samen met de output (Y) die die input geeft. f(X) = Y dus. In de praktijk zul je altijd een afwijking (error) hebben en daarom schrijven we Y = f(x) + e.
Oefenen met een supervised machine learning tutorial? Bekijk dan dit artikel
De foutmarge van een machine learning model bestaat altijd uit drie verschillende componenten:
- De error door bias
- De error door variance
- Een onherleidbare error
Ieder model zal een bepaalde mate hebben van een onherleidbare error, hoe goed je je model ook maakt. Dit kan verschillende oorzaken hebben. Denk bijvoorbeeld aan de invalshoek (en variabelen) die je voor je voorspelmodel hebt gekozen, missende of foutieve input of output data waarmee je het model traint.
De errors die je wél kunt beïnvloeden met keuzes voor jouw te benaderen doelfunctie (f) zijn de bias en de variantie. We zullen bespreken wat bias en variantie inhouden en vervolgens de tradeoff bespreken.
Wat is bias?
De bias kan gedefinieerd worden als het verschil tussen de gemiddelde voorspelde waarde door een model en de correcte (echte) waarde die getracht wordt te voorspellen.
Een model met een hoge bias wijkt dus veel af van de echte te voorspellen waarden in de trainingsdata. Het resultaat is dan een sterk versimpeld model met een hoge foutmarge.
Een algoritme introduceert dus aannames in de doelfunctie (f) om de functie simpel en snel (want makkelijk) te houden. Algoritmes als lineaire regressie of logistic regression introduceren veelal een hoge bias. Algoritmes als k-Nearest Neighbors, Support Vector Machines, of Decision Trees introduceren veelal een lage bias.
Wat is variance?
Variantie kunnen we begrijpen als de variabiliteit voor voorspellingen van een model. Een model met een hoge variantie zal veel aandacht hebben voor verbanden in de training data, maar heeft het lastig om voor nieuwe data correcte voorspellingen te doen. Een model met hoge variantie generaliseert dus niet goed.
Kort gezegd kun je stellen: als je lage variantie hebt dan zullen kleine wijzigingen in de training data leiden tot kleine wijzigingen in de doelfunctie (f), terwijl bij hoge variantie kleine wijzigingen in de training data leiden tot grote wijzigingen in de doelfunctie (f).
Flexibele niet-lineaire algoritmes hebben vaak hogere variantie, zoals bijvoorbeeld k-Nearest Neighbors of Support Vector Machines.
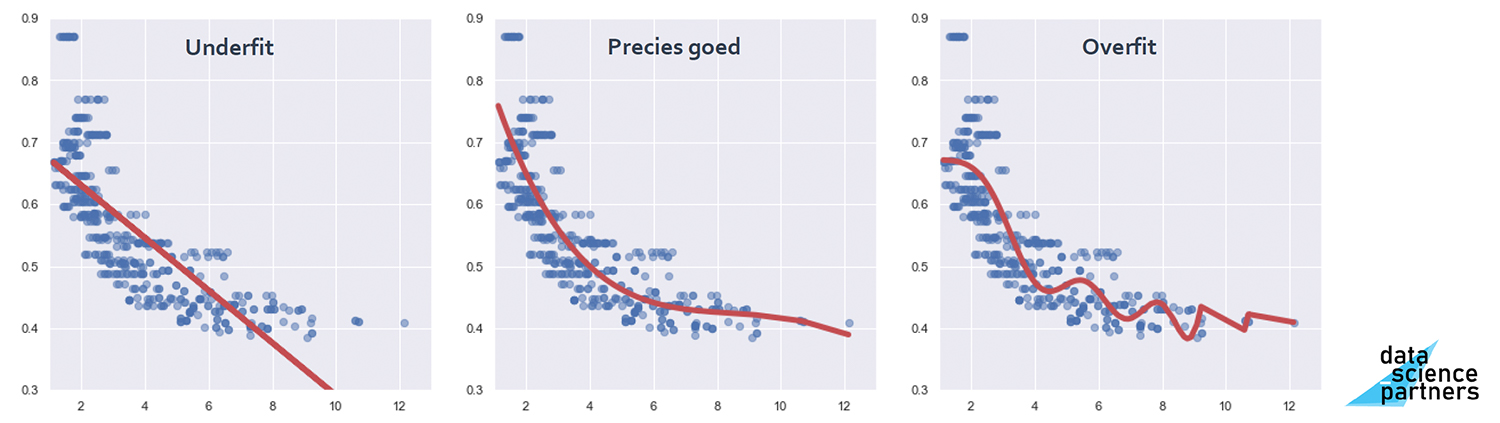
links: hoge bias (underfit), midden: goede balans tussen bias en variantie, rechts: hoge variantie (overfit)
Wat is de Bias-Variance Tradeoff?
In bovenstaande afbeelding zie je de afweging tussen bias en variantie grafisch weergegeven. Als je teveel bias introduceert maakt je model een te simpele voorspelling (underfitting) terwijl als je te weinig bias introduceert je een situatie van overfitting realiseert omdat het model de onderliggende verbanden niet goed uit de training data weet te halen.
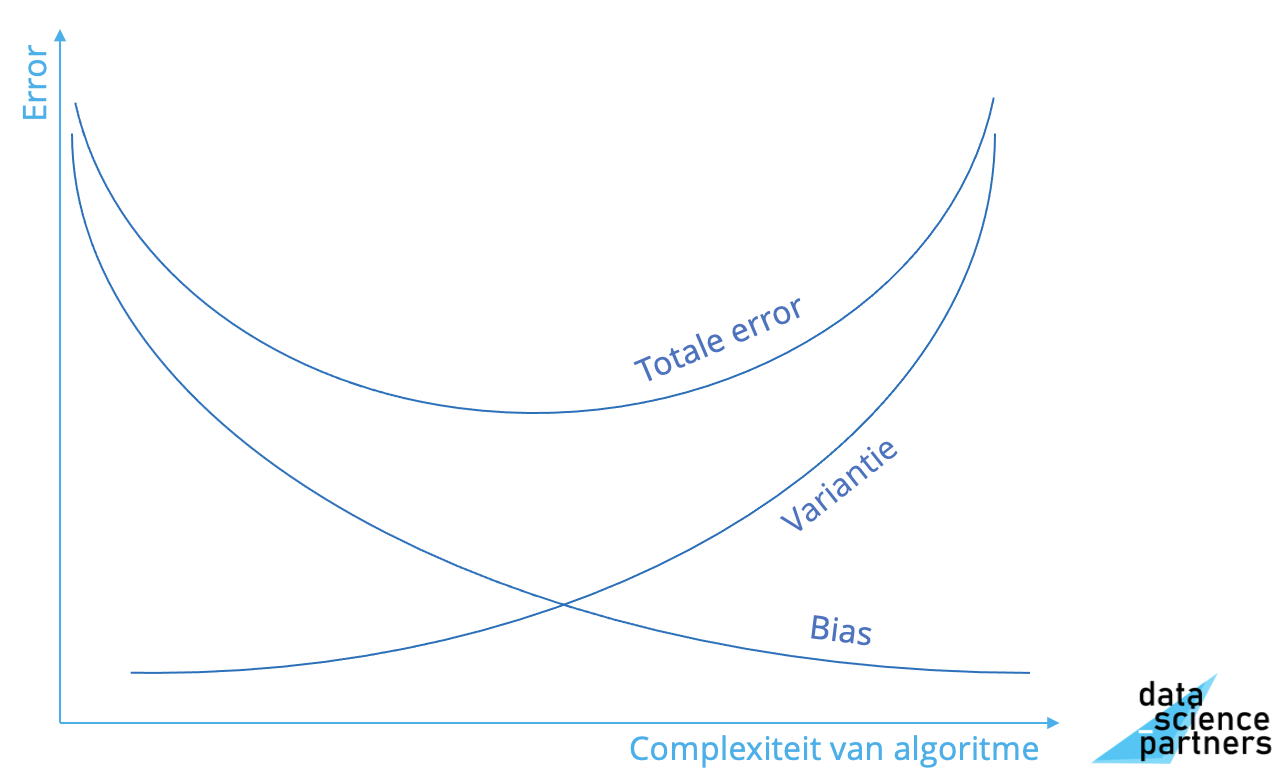
Uiteindelijk wil je een situatie hebben waarbij de totale foutmarge in de voorspellingen van jouw model minimaal is. Dit kun je doen door de error die ontstaat door bias op te tellen bij de error die ontstaat door variantie. Deze totale error wil je minimaliseren zoals onderstaande grafiek weergeeft. Bij een minimale totale error zijn variantie en bias optimaal in balans.
Over het algemeen zul je veel testen met verschillende configuraties als je een machine learning model ontwikkelt. Dit noem je ook wel hyperparameter optimalisatie. Ieder supervised machine learning algoritme kent een eigen manier van het optimaliseren van het model. Zo kun je bijvoorbeeld bij het k-Nearest Neighbors algoritme spelen met het aantal neighbors waarbij je meer bias introduceert met meer neighbors.
In onze machine learning training en data science opleiding gaan we zelf aan de slag met het ontwikkelen van machine learning modellen. Hierin komt de bias-variance tradeoff ook langs. Dus wil jij je ontwikkelen of omscholen tot data scientist en in staat zijn om nog nauwkeurigere voorspellingen te doen? Schrijf je dan in of neem contact met ons op voor meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Rik is data scientist en marketeer bij Data Science Partners. Vanuit zijn achtergrond op de Technische Universiteit Eindhoven heeft hij veel affiniteit met data. Na zijn studie heeft hij als consultant altijd met data gewerkt en tevens ervaring opgedaan in het geven van trainingen.