Een histogram in R vertegenwoordigt de verdeling van numerieke gegevens. De vorm van het histogram is vergelijkbaar met een staafdiagram en toont de frequentie van de gegevens. Met andere woorden; de frequentie waarmee bepaalde waarden in een bepaalde dataset voorkomen. Een histogram is een essentieel hulpmiddel in de toolbox van elke data scientist. Voordat je als datawetenschapper data gaat verwerken, is het belangrijk om een gevoel en een duidelijk beeld van de data te krijgen. Daarom is het maken van een histogram vaak een goede start. Op deze manier kan de data visueel worden gemaakt en krijg je er gevoel bij.
We gebruiken in dit blog de software R. Heb je R nog niet geïnstalleerd, volg dan onze handleiding om R te installeren
In dit blog zullen de volgende stappen worden besproken:
- Wat is een R histogram?
- Onze dataset
- Standaard R histogram
- Histogram met ggplot2
- Wat gebruik je wanneer?
Wat is een histogram?
Stel dat je de lengte van mannen in de stad wilt bestuderen. Je vraagt aan 100 mannen hoe lang elke is, waarna je hun antwoorden opschrijft. Na thuiskomst maak je de volgende tabel:
| Man # | Lengte (cm) |
|---|---|
| 1 | 160 |
| 2 | 158 |
| 3 | 143 |
| 4 | 164 |
| 5 | 161 |
| ... | ... |
| 100 | 157 |
Deze tabel is theoretisch gezien een bepaalde weergave van je verzamelde data. Deze weergave heeft alleen een groot probleem: het is niet erg overzichtelijk. Het is moeilijk om de verbanden te zien of bepaalde conclusies te trekken. In dit geval heb je "maar" met 100 mannen te maken, en je kunt je voorstellen hoe onmogelijk deze taak is voor een grotere dataset.
Om de verdeling van de verschillende lengtes toch duidelijker te maken, kun je een histogram maken. Je kiest een bepaalde stapgrootte of "bin". In dit geval heb je te maken met lengte, dus een bin van 10 cm kan goed werken. Dit betekent dat de volledige dataset in deze bins wordt opgedeeld. Als de minimale lengte in de data 140 cm is en de maximale lengte 170 cm, dan krijg je de bins 140-150, 150-160, 160-170. Hierna bepaal je voor elke observatie in welke bin deze hoort.
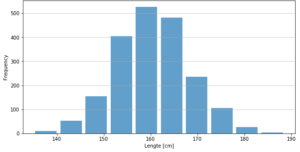
Aan de hand van deze histogram kun je goed aflezen dat de gemiddelde lengte van de ondervraagde mannen 160cm is. Bovendien valt duidelijk te zien dat de data redelijk normaal is verdeeld. Dit is belangrijk om te zien omdat veel statistische en analytische methodes data met een normaalverdeling vereisen. Verder kun je snel zien dat de groep mannen die groter is dan het gemiddelde (160cm) ongeveer even groot is als de groep mannen die kleiner is dan het gemiddelde.
Data
Om een R histogram te kunnen maken heb natuurlijk data nodig. Je kunt hiervoor een bestaande dataset gebruiken, maar om het simpel te houden gaan we in dit geval zelf data genereren. Met R kun je simpel willekeurige data genereren volgens een bepaalde verdeling. In dit geval kiezen we voor de normaalverdeling. Met de functie rnorm() worden deze willekeurige waarden gegenereerd. Hierbij geven we het gemiddelde en de standaarddeviatie op.
data <- rnorm(100, mean=160, sd=8)Belangrijk: Alle code die wij hier gebruiken kun je vanuit de console uitvoeren. Wij raden echter aan om het in een R Script te bewaren. Zo kun je goed elke stap bijhouden. Begrijp je niet goed wat we hiermee bedoelen, lees dan eerst onze handleiding van RStudio.
R Histogram met de standaard R functionaliteit
R heeft, in tegenstelling tot bijvoorbeeld Python, heel veel gebruiksvriendelijke ingebouwde functionaliteiten wat betreft visualisatie. Zo zijn er niet perse extra packages nodig om binnen R een histogram te creëren. Deze standaard functionaliteit wordt dan ook veelvuldig gebruikt om grafieken en andere weergaven van data te kunnen maken. Binnen R is zo ook de functie hist() aanwezig. Deze kun je uitvoeren en bovendien verschillende argumenten meegeven, waaronder de data en het aantal breaks (bins). Nu gaan we deze functie hist() gebruiken om een histogram te maken van de eerder gemaakte dataset.
hist(data, breaks=5)
Om de leesbaarheid van de grafiek te verbeteren geven we de histogram een titel. Dit doe je op de volgende manier.
hist(data, breaks=5, main='Histogram van Lengte Mannen') 
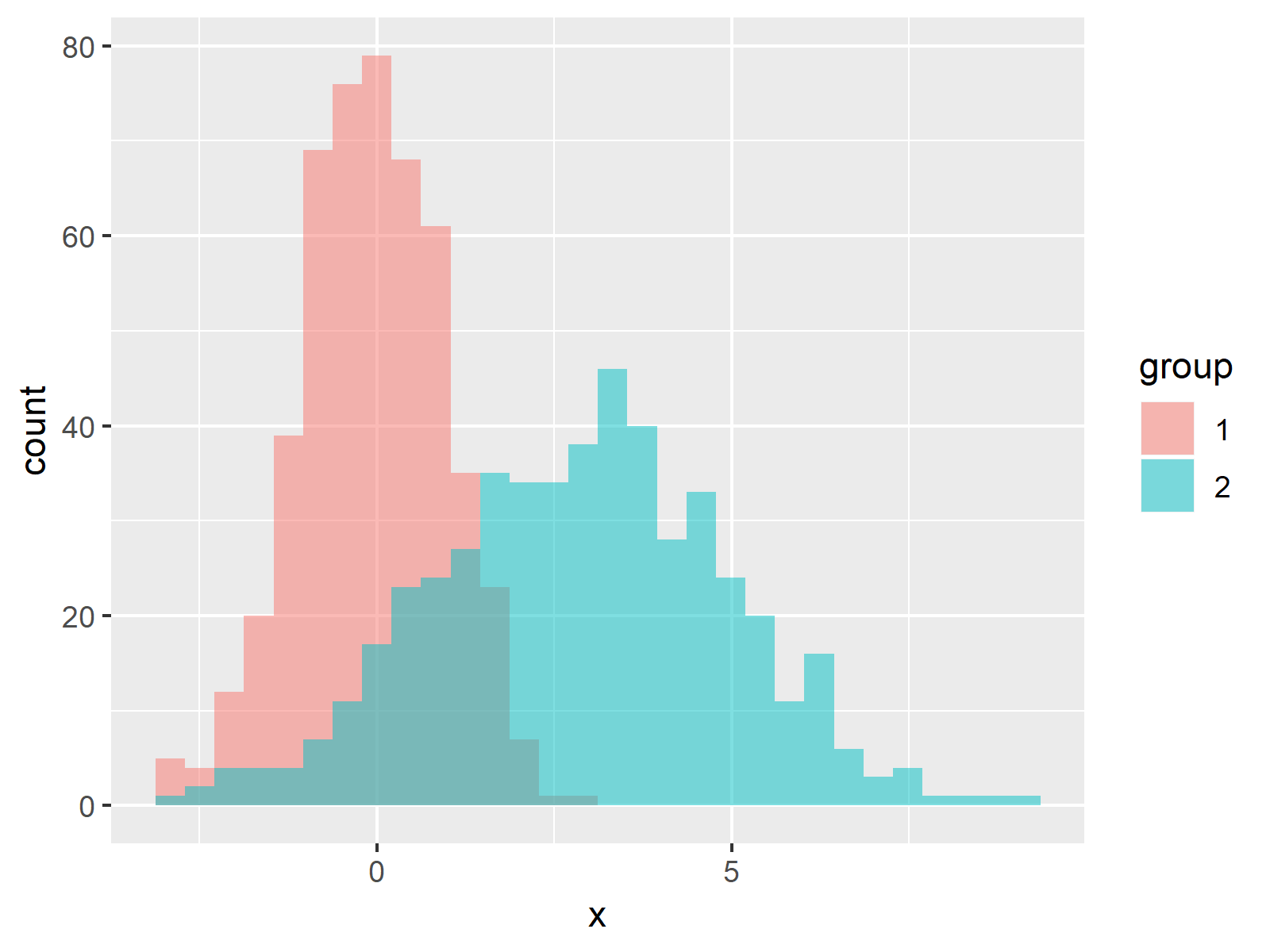
Een histogram kan ook gebruikt worden om onderling de verdeling tussen twee datasets te vergelijken. Zo kan het bijvoorbeeld interessant zijn om de verdeling in lengte van mannen met die van vrouwen te vergelijken. Het ziet er wat rommelig uit en bovendien zitten de rode kolommen in de weg van de blauwe die hierachter verstopt zitten. Dit is precies een van de redenen om een ander package (zoals ggplot2) te gebruiken. De functionaliteiten binnen het basis R zijn namelijk beperkt.
mannen <- rnorm(mean=10, n = 1000)
vrouwen <- rnorm(mean=11, n = 1000)
hist(mannen, col='blue', main='Bright colors, visible overlap', xlab="Verdeling Mannen & Vrouwen")
hist(vrouwen, col='red', add=T) 
R Histogram met ggplot2
Ggplot2 is een R package en is een aanvulling op de standaard functionaliteit binnen R. Het hoort (net als bijvoorbeeld dplyr bij de samenstelling van packages genaamd Tidyverse. Hiermee kun je, in tegenstelling tot de standaard visualisaties van R, geavanceerde visualisaties van data maken. Om een voorbeeld te geven van zo’n geavanceerde visualisatie nemen wij de kdeplot. Dit een visualisatie van een Kernel Density Estimation (KDE). KDE is simpel gezegd een manier om een kansdichtheidsfunctie van een dataset op te stellen. Je kunt het zien als een histogram waarbij de scherpe hoeken van de staven zijn vervangen door een vloeiende en doorlopende lijn. In het volgende voorbeeld laten we zien hoe je combinatie van een histogram en een kdeplot kunt creëren door middel van ggplot2.
library(ggplot2)
library(tidyr)
df <- data.frame(mannen = rnorm(1000, 10), vrouwen = rnorm(1000, 13)) %>%
gather(key, value)
ggplot(df, aes(value, colour = key)) +
geom_histogram(aes(y=..density.., fill=key),position="identity", alpha=0.2, binwidth = 0.3, ) +
geom_density() +
theme_minimal() 
Je ziet nu naast de rode en blauwe staven van de histograms ook de rode en blauwe lijnen van de KDE plots. Zo kan er nog meer inzicht in de dataset worden gecreëerd. Bovendien kun je direct zien dat de grafieken van ggplot2 er mooier en professioneler uitzien.
Wanneer gebruik je precies wat?
Een histogram biedt een helder inzicht in de distributie van numerieke data. R biedt verschillende mogelijkheden om histogrammen te maken:
- Data is door middel van standaard functionaliteit binnen R simpel om te zetten naar een histogram.
- Ggplot2 biedt geavanceerde tools voor ingewikkeldere inzichten en ziet er esthetisch aantrekkelijker uit.
Wil jij goed leren werken in R? Tijdens onze Opleiding R leer je alles wat je nodig hebt om zelfstandig analyses uit te voeren in R.

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.









