Wanneer je met ruimtelijke, geografische data werkt kun je veel verschuilende analyses en bewerkingen doen met softwarepakketten zoals ArcGIS.
Naast dat je voor softwarepakketten kunt kiezen, is werken met GIS data met programmeertaal Python ook een mogelijkheid. Voordelen hiervan zijn onder andere dat Python opensource is waardoor je geen licentiekosten hoeft te betalen, en dat je de handelingen die uitgevoerd moeten worden eenvoudig kunt automatiseren.
Om in Python met GIS data aan de slag te kunnen heb je diverse specifieke GIS packages nodig. Packages hebben zelf vaak ook weer andere packages nodig om te kunnen werken. Wanneer je met GIS packages werkt is het aan te raden om gebruik te maken van Anaconda. Hiermee kunnen de benodigde packages het makkelijkst geïnstalleerd worden.
In deze Python GIS tutorial gaan we stap voor stap GIS datasets openen, coördinaten referentiesystemen bekijken, datasets samenvoegen en inzichten visualiseren. Dit doen we vanuit een voorbeeld waarin we het gemiddelde huishoudinkomen per provincie gaan visualiseren.
Dataset geografische provinciegrenzen
We gaan een GIS dataset openen die per provincie de geografische grenzen per provincie bevat. Dit is een dataset afkomstig van het CBS. Je kunt alle data voor deze tutorial hier downloaden. Om een GIS dataset te openen maken we gebruik van package GeoPandas. Dit is een handig package om met ruimtelijke datasets te kunnen werken in Python. Het bouwt voort op de functionaliteit van package Pandas, en breidt dit uit met ruimtelijke eigenschappen in een specifieke kolom "geometry".
import warnings
warnings.filterwarnings('ignore')
import geopandas as gpd
file_path = 'data/provincies/B1_Provinciegrenzen_van_NederlandPolygon.shp'
gdf_prov = gpd.read_file(file_path)
print(type(gdf_prov))
print(gdf_prov.shape)
gdf_prov
Methoden en attributen
We zien dat het een GeoDataFrame object is. Ook zien we dat dit uit 12 rijen en 4 kolommen bestaat, waaronder de kolom "geometry", die per provincie de geografische grenzen bevat. Je ziet hier 2 soorten ruimtelijke objecten: Polygon en MultiPolygon. Dit zijn objecten vanuit package Shapely waar je vanuit GeoPandas gebruik van kunt maken. Hierdoor kun je bijvoorbeeld gemakkelijk oppervlaktes berekenen, zoals we in onderstaand voorbeeld doen.
gdf_prov['area'] = gdf_prov.area
gdf_prov.head()
Coördinaten referentiesysteem (CRS)
Om oppervlaktes te kunnen berekenen is het wel belangrijk dat het coördinaten referentiesysteem (CRS) juist is ingesteld. Dit is gemakkelijk te bekijken met het .crs attribuut.
gdf_prov.crs
Indien je dit zou willen wijzigen kan dit met de .to_crs() methode, waarin je het nieuwe CRS opgeeft.
Plotten van ruimtelijke vormen
Door gebruik te maken van package Matplotlib kunnen de geografische vormen snel weergegeven worden. Hier stellen we een grenskleur in en geven de vormen geen vulkleur.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8,8))
gdf_prov.plot(ax=ax, facecolor='none', edgecolor='gray')
plt.show()

Dataset inkomen per provincie
Nu weten we wat de grenzen van provincies zijn, maar we missen de gegevens met huishoudensinkomens nog. Hiervoor openen we een extra dataset. Met package Pandas openen we deze dataset die per provincie het gemiddelde huishoudensinkomen per jaar bevat. We zien dat er 12 rijen en 2 kolommen zijn.
import pandas as pd
file_path = 'data/bruto_huishoudensinkomen.xlsx'
df_inkomen = pd.read_excel(file_path)
print(df_inkomen.shape)
df_inkomen
Datasets samenvoegen
Een overeenkomst tussen de twee datasets is dat ze allebei een kolom met de provincienamen bevatten. We gebruiken deze kolommen om de datasets samen te voegen. Dit doen we met package Pandas. Let er hierbij op dat het GeoPandas GeoDataFrame als eerste benoemd wordt.
gdf_prov = pd.merge(gdf_prov, df_inkomen, left_on='PROV_NAAM', right_on='Provincie', how='left')
print(type(gdf_prov))
gdf_prov
We zien nu dat het resultaat nog steeds een GeoDataFrame is, nu voorzien van de inkomensdata.
Plotten van de inkomensdata
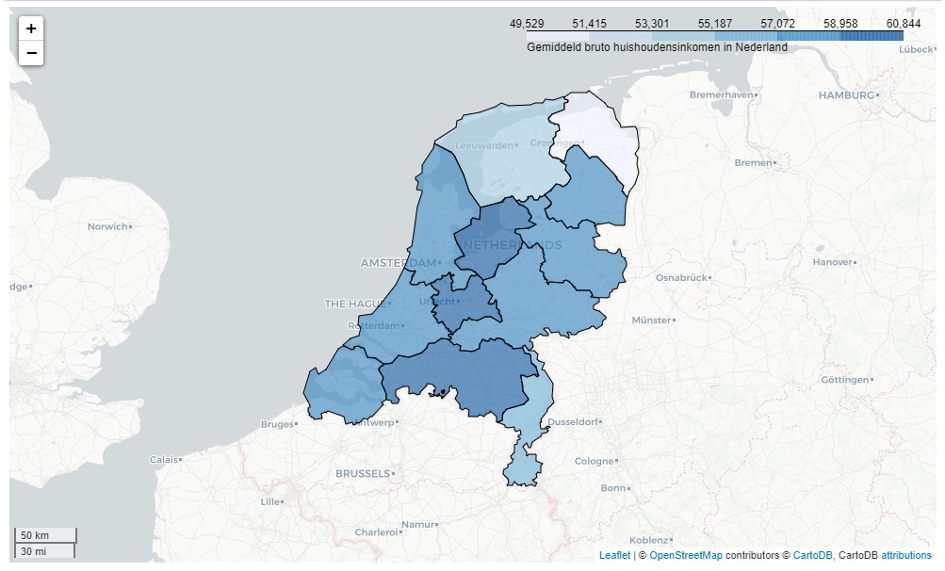
De verschillende inkomens per provincie kunnen nu gevisualiseerd worden met Matplotlib.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8,8))
column = 'Gemiddeld bruto huishoudensinkomen'
gdf_prov.plot(ax=ax, edgecolor='gray', column=column, legend=True);

Reclassificeren
Wanneer we de inkomens willen groeperen, en dit willen visualiseren, kunnen we gebruik maken van reclassificatie. Dit doen we in onderstaand voorbeeld door gebruik te maken van kwantielen, maar je kunt ook voor andere verdelingen kiezen. Je doet dit door een "scheme" te kiezen. Verder selecteren we een specifieke kleurenkaart waardoor lage inkomens lichter blauw zijn en hogere inkomens donkerder blauw.
column = 'Gemiddeld bruto huishoudensinkomen'
fig, ax = plt.subplots(figsize=(8,8))
gdf_prov.plot(column=column, scheme='Quantiles', k=5, edgecolor='gray', cmap='Blues', legend=True, ax=ax);

Hiermee hebben we al mooi zichtbaarheid gegeven aan de huishoudensinkomens in de provincies.
Interactieve kaart
Tot slot maken we naast de statische plots ook nog een interactieve plot. Hiervoor gebruiken we package Folium.
Data voorbewerken
Om met Folium te kunnen werken moet de data aan bepaalde voorwaarden voldoen, die doen we met onderstaande code. We voegen een "geoid" toe als eerste kolom, en selecteren de kolommen die we nodig hebben.
gdf_prov_choro = gdf_prov.copy()
gdf_prov_choro['geoid'] = gdf_prov_choro.index.astype(str)
gdf_prov_choro = gdf_prov_choro[['geoid', 'Gemiddeld bruto huishoudensinkomen', 'PROV_NAAM', 'geometry']]
gdf_prov_choro.head(3)
Centerpunt
Vervolgens definiëren we een centerpunt waarop de kaart cal centreren. Dit doen we in Tuple formaat.
nld_lat = 52.2130
nld_lon = 5.2794
nld_coordinates = (nld_lat, nld_lon)
Kaart van Nederland
Allereerst maken we een lege kaart van Nederland, hierbij maken we gebruik van het centerpunt. Verder kiezen we het type kaart, de detailgraad en voegen een schaalaanduiding toe. Dit doen we met de volgende code.
import folium
# Maak kaart van Nederland
map_nld = folium.Map(location=nld_coordinates, tiles='cartodbpositron', zoom_start=7, control_scale=True)
# Toon resultaat
map_nld
Inkomensdata toevoegen
Aan deze kaart voegen we de inkomensdata toe. We selecteren de data, stellen een blauwe kleurenkaart in, en voegen een legenda toe.
# Voeg inkomensdata toe
folium.Choropleth(geo_data=gdf_prov_choro,
data=gdf_prov_choro,
columns=['geoid', 'Gemiddeld bruto huishoudensinkomen'],
key_on='feature.id',
fill_color='Blues',
legend_name='Gemiddeld bruto huishoudensinkomen in Nederland'
).add_to(map_nld)
# Toon resultaat
map_nld
De interactieve kaart die volgt als output van deze code is te zwaar voor deze pagina maar kan bijvoorbeeld binnen Jupyter Notebook bekeken worden.
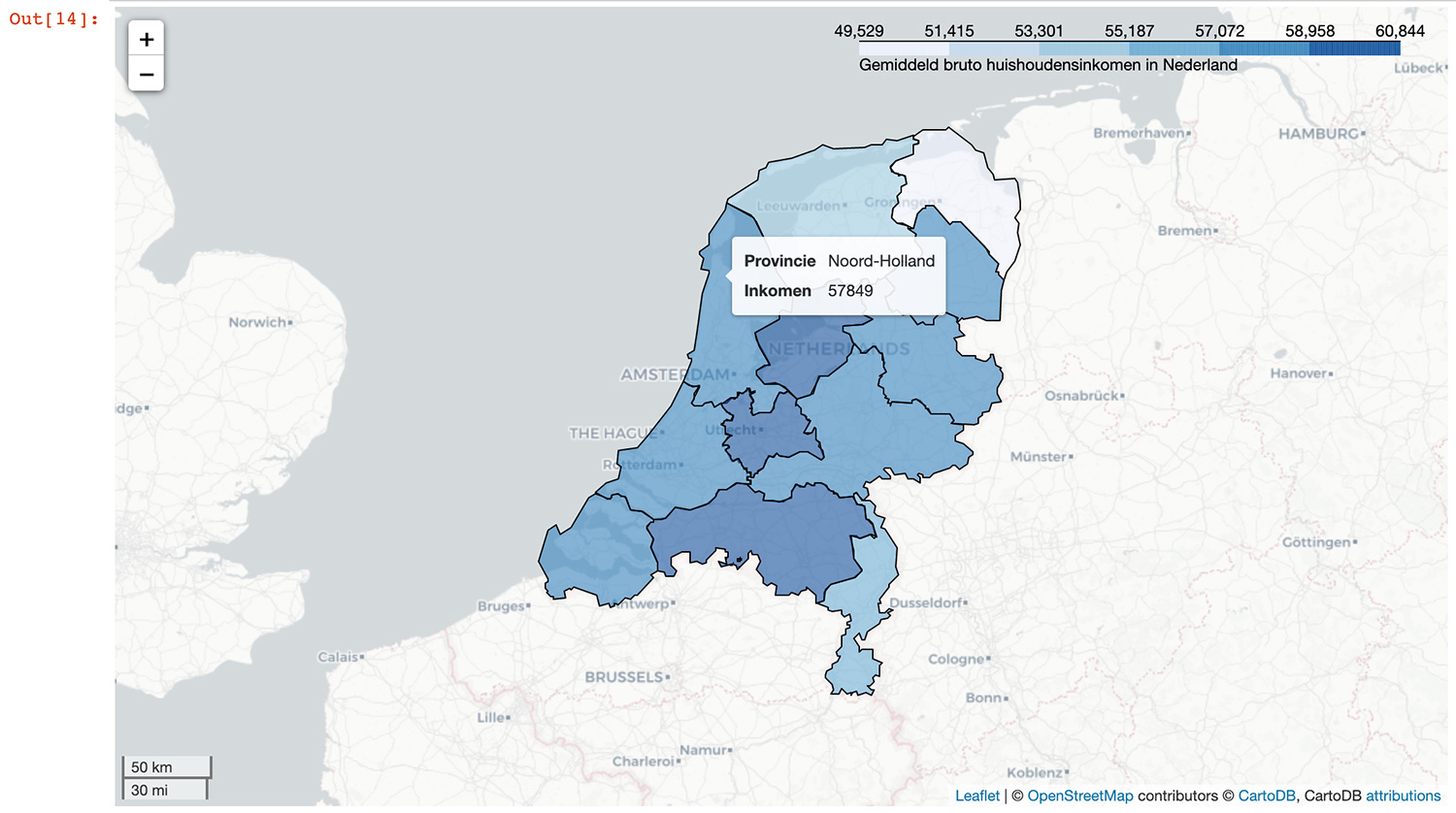
Tooltips toevoegen
Tot slot voegen we tooltips toe, zodat wanneer je met de muis over een provincie beweegt je relevante data te zien krijgt. Hierbij laten we de naam van de provincie zien, en het bijbehorende gemiddelde huishoudensinkomen.
# Voeg tooltips toe
folium.features.GeoJson(data=gdf_prov_choro,
style_function=lambda x: {'color':'transparent','fillColor':'transparent','weight':0},
tooltip=folium.features.GeoJsonTooltip(fields=['PROV_NAAM', 'Gemiddeld bruto huishoudensinkomen'],
aliases=['Provincie', 'Inkomen'],
labels=True)
).add_to(map_nld)
# Toon resultaat
map_nld
Ook de output van deze code kunnen we niet op deze pagina laten zien, maar kun je wel zelf runnen.
Wat je moet onthouden
Met package GeoPandas kunnen we ruimtelijke datasets openen, bewerkingen doen en analyses verrichten. We kunnen datasets samenvoegen om eigenschappen te combineren. GeoPandas maakt gebruik van de ruimtelijke objecten vanuit package Shapely en bewaart dit in een specifieke kolom "geometry". Met hulp van package Matplotlib kan ruimtelijke data eenvoudig worden gevisualiseerd. Hierbij kan de data ook gereclassificeerd worden. Met package Folium kunnen interactieve visualisaties gemaakt worden, zodat we in ons voorbeeld de details per provincie goed konden bekijken.
Wil je met GIS packages leren werken? Neem dan contact op over onze in-company GIS training. Wil je meer leren over data analyse met Python? Schrijf je dan in voor onze Python cursus voor data science, onze machine learning training, of voor onze data science opleiding en leer met vertrouwen te programmeren en analyseren in Python.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.