Het k-Nearest Neighbor (kNN) algoritme geeft de mogelijkheid om datasets in groepen te verdelen op basis van de dichtstbij gelegen datapunten. Letterlijk betekent Nearest Neighbor dan ook dichtstbijzijnde buur. Er is altijd een referentie-dataset nodig, hierdoor valt het kNN algoritme binnen Supervised Learning binnen het gebied van machine learning. Als data scientist gebruik je het k-Nearest Neighbor algoritme om (i) waarden te voorspellen (regressie) of (ii) om een groep/label te bepalen (classificatie).
Het k-Nearest Neighbor (kNN) algoritme geeft de mogelijkheid om datasets in groepen te verdelen op basis van de dichtstbij gelegen datapunten
Uitleg over het k-Nearest Neighbor algoritme
Om het algoritme uit te leggen kijken we naar de toepassing van kNN bij een data science classificatievraagstuk.
We nemen het volgende voorbeeld, waarbij we een dataset hebben met bloemensoorten:
- setosa
- versicolor
- virginica
We hebben meetgegevens van de lengte van bloembladeren, breedte van bloembladeren en de toewijzing van het bloemensoort. Als we in een grafiek lengte op de x-as zetten, breedte op de y-as, en datapunten van een verschillende bloemensoort een andere kleur geven krijgen we onderstaande grafiek:
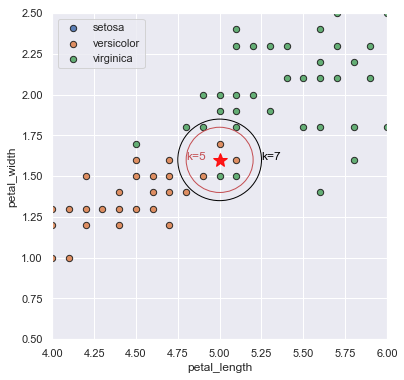
We kunnen nu gebruik maken van deze data om voor een nieuw datapunt (zie ster in de grafiek), afhankelijk van een gekozen aantal dichtstbijzijnde datapunten (Nearest Neighbors), het plantensoort te berekenen.
- Stel we kiezen als aantal Nearest Neighbors k=5, dan zijn de dichtstbijzijnde datapunten als volgt: 3 keer versicolor en 2 keer virginica. Hierdoor krijgt ons datapunt de classificatie versicolor.
- Stel we kiezen als aantal Nearest Neighbors k=7, dan zijn de dichtstbijzijnde datapunten als volgt: 3 keer versicolor en 4 keer virginica. Hierdoor krijgt ons datapunt de classificatie virginica.
We zien direct al in het voorbeeld dat door een andere waarde voor k te kiezen de voorspelling anders kan zijn. Deze waarde dient dan ook slim gekozen te worden. Dit kun je bijvoorbeeld doen door voor verschillende waarden een model te trainen en de prestaties van deze verschillende modellen te vergelijken door voorspellingen te doen op train- en testdata. Vervolgens kun je een waarde kiezen waarbij het model goed presteert op zowel de train- als testdata. Hiermee voorkom je under- en overfitting.
Over het algemeen is een kNN niet het meest nauwkeurig, maar wel erg snel op met name kleine datasets. Doordat je goed kan visualiseren wat het model doet is het ook goed te begrijpen en daardoor makkelijk uit te leggen aan anderen. Binnen Machine Learning wordt een kNN model ook wel gebruikt om missende waarden in datasets op te vullen.
Hoe gebruik ik k-Nearest Neighbor in Python?
In deze tutorial gaan we stap voor stap het kNN algoritme toepassen om een model te trainen voor een classificatievraagstuk. Dit doen we met een Python script.
We werken hier met de bekende iris dataset, een dataset met meetgegevens van bloemen en de toewijzing welke soort iris het betreft. Dit kan een van de volgende soorten zijn: setosa, virginica of versicolor.
Hierbij behandelen we de volgende stappen:
- Onderzoeksvraag
- Data verzamelen
- Data voorbewerken
- Algoritme kiezen
- Model trainen
- Model beoordelen
Onderzoeksvraag
Wanneer we een verzameling meetgegevens van irisbloemen hebben, willen we kunnen voorspellen welk type iris (setosa, virginica of versicolor) van toepassing is op een meting.
Data verzamelen
De iris dataset is te importeren vanuit package Scikit-Learn. We doen dit als volgt:
from sklearn import datasets
iris = datasets.load_iris()
In deze dataset zijn de volgende eigenschappen (features) beschikbaar:
iris.feature_names
Het irissoort (setosa, virginica of versicolor) is al beschikbaar als numerieke waarde.
iris.target
iris.target_names
We kunnen nu alvast een grafiek maken van deze data.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set(color_codes=True)
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(1,1,1)
for index, target_name in enumerate(iris.target_names):
ax.scatter(X[y == index, 0], X[y == index, 1], s=40, alpha=0.9, edgecolors='k', label=target_name)
ax.set_xlabel('petal_length')
ax.set_ylabel('petal_width')
ax.legend()
plt.show()

Data voorbewerken
We selecteren de eerste twee kolommen ('sepal length (cm)' en 'sepal width (cm)') als features: de X-waarden. Als target selecteren we de irissoort.
X = iris.data[:, 2:]
y = iris.target
Vervolgens delen we de data op in 80% train- en 20% testdata. Met de traindata trainen we het model, de testdata gebruiken we om het model te valideren.
Hiervoor gebruiken we de methode train_test_split() uit package Scikit-Learn. Het argument stratify=y gebruiken we om in zowel de train- als testdata een gelijke verdeling van irissoorten te krijgen.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
Algoritme kiezen
Vanuit package Scikit-Learn gebruiken we het algoritme KNeighborsClassifier.
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
clf
We zien dat dit algoritme standaard naar 5 neighbors kijkt (parameter n_neighbors).
Model trainen
Met de methode .fit() trainen we het model met de traindata.
clf.fit(X_train, y_train)
Model beoordelen
Met de methode .predict() kunnen we nu voor waarden voor 'sepal length (cm)' en 'sepal width (cm)' voorspellingen doen. We doen een voorspelling voor 'sepal length (cm)' = 4cm en 'sepal width (cm)' = 1cm.
clf.predict([[4,1]])
Dit zou irissoort versicolor moeten zijn. We controleren dit visueel door een grafiek te maken:
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set(color_codes=True)
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(1,1,1)
for index, target_name in enumerate(iris.target_names):
ax.scatter(X_train[y_train == index, 0], X_train[y_train == index, 1], s=40,
alpha=0.9, edgecolors='k', label=target_name)
ax.plot(4, 1, c='red', alpha=0.9, marker='*', markersize=15);
ax.set_xlabel('petal_length')
ax.set_ylabel('petal_width')
ax.legend()
plt.show()

Dat ziet er goed uit.
Nu bekijken we de nauwkeurigheid (percentage juiste voorspellingen) van het model door dit te bepalen voor voorspellingen op de train- en testdata. Als eerste maken we voorspellingen voor de train- en testdata.
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
Vervolgens gebruiken we accuracy_score() vanuit package Scikit_Learn om de nauwkeurigheid te bepalen.
from sklearn.metrics import accuracy_score
print('Accuracy traindata')
print(accuracy_score(y_train, y_pred_train))
print('')
print('Accuracy testdata')
print(accuracy_score(y_test, y_pred_test))
Ook dit ziet er goed uit. Het model voorspelt op zowel de train- als testdata in meer dan 95% van de gevallen de juiste irissoort. We hebben nu succesvol een kNN model getraind op testdata, en hebben vervolgens hiervan de nauwkeurigheid vergeleken door met het model voorspellingen te doen op train- en testdata.
Wat je moet onthouden over het k-Nearest Neighbor algoritme
Het k-Nearest Neighbor (kNN) algoritme is een Supervised Learning algoritme: er is een dataset met bekende uitkomsten nodig om het algoritme toe te passen. Nearest Neighbor betekent dichtstbijzijnde buur, en het algoritme bepaalt het gemiddelde van de k dichtstbijgelegen datapunten om voor een bepaald datapunt een voorspelling te doen. Het kNN algoritme kan zowel gebruikt worden voor classificatie- als regressievraagstukken. Het is niet het nauwkeurigste algoritme maar is erg snel en makkelijk uit te leggen aan anderen.
Met Python kun je eenvoudig een kNN algoritme toepassen om een model te maken door gebruik te maken van KNeighborsClassifier uit package Scikit-Learn. Hiermee kun je vervolgens met de methode .fit() een model trainen, en met predict.() een voorspelling doen.
Een kNN model stap voor stap toepassen met Python is onderdeel van onze machine learning training en data science opleiding. Dus wil jij je ontwikkelen of omscholen tot data scientist en in staat zijn om nog nauwkeurigere voorspellingen te kunnen doen? Schrijf je dan in of neem contact met ons op voor meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.