De term "Large Language Model" (LLM) is de laatste jaren steeds vaker te horen, vooral door de opkomst van AI-tools zoals ChatGPT. Maar wat is een het precies, en hoe werkt het? In deze blogpost geven we hier een eenvoudige uitleg van. We kijken ook naar een concreet voorbeeld om de werking van een LLM te laten zien.
1. Wat is een Large Language Model?
Een Large Language Model (LLM) is een specifieke techniek binnen kunstmatige intelligentie (AI). Een LLM kan teksten en opdrachten interpreteren en kan vervolgens nieuwe teksten genereren. Zo'n model is “large” (groot) omdat op enorme hoeveelheden tekstdata is getraind, zoals boeken, artikelen en websites, en daarin patronen heeft ontdekt deze heeft opgeslagen. Dit maakt het model in staat om allerlei soorten teksten te begrijpen, vragen te beantwoorden, zinnen af te maken, en nieuwe teksten te generen die menselijk overkomen.
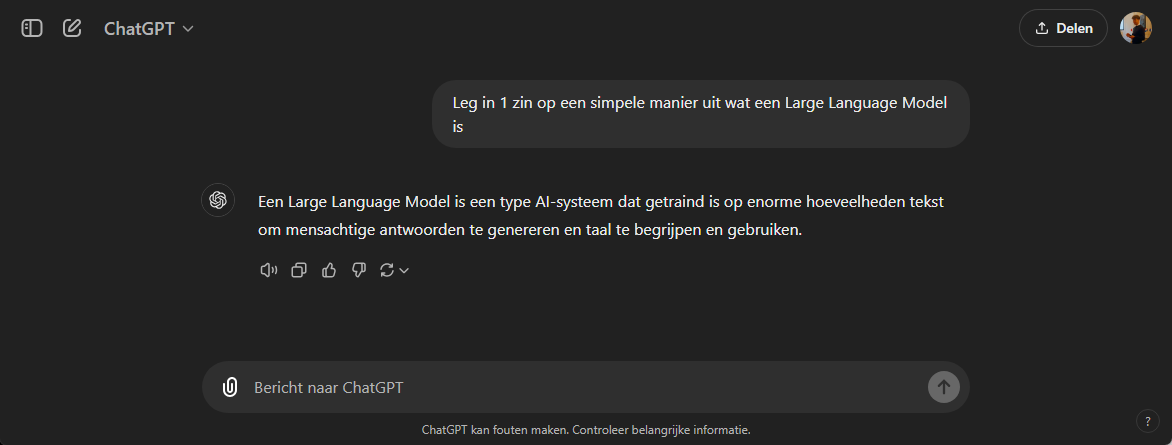
Zo kun je bijvoorbeeld ChatGPT ook vragen wat een Large Language model is:
Kort samengevat: een LLM gebruikt complexe wiskundige berekeningen om patronen in taal te leren en die patronen toe te passen op nieuwe situaties. Dit stelt zo'n model in staat om zeer menselijke antwoorden te geven op een breed scala aan vragen.
2. Hoe werkt een Large Language Model?
De basis van een LLM is een techniek die machine learning heet. Met machine learning leert een computermodel zelfstandig patronen te ontdekken in data. Dit kunnen verschillende soorten data zijn zoals cijfers of afbeeldingen. In het geval van een LLM is dit tekstdata, zoals bijvoorbeeld boeken, Wikipedia, of internetfora als Reddit. Om tot een LLM te komen worden enkele stappen doorlopen:
Stap 1: Training
Een LLM zoals het model dat ChatGPT gebruikt is getraind op grote hoeveelheden bestaande teksten (bijvoorbeeld boeken, artikelen, websites, etc.). Dit is het proces waarbij het model patronen ontdekt vanuit de teksten. Om zowel kennis over taal te verkrijgen, als om kennis over specifieke onderwerpen op te doen. Versimpeld weergegeven werkt het traingsproces als volgt:
- Het model verwerkt een bestaande tekst, en bekijkt hierin woord voor woord in iedere zin.
- Het model voorspelt ieder volgend woord in een zin.
- Het model vergelijkt de voorspelling met het werkelijke woord, als de voorspelling fout is wordt het model aangepast.
- Door het verwerken van grote hoeveelheden tekst, en daardoor ook vele aanpassingen aan het model, wordt het steeds nauwkeuriger in het voorspellen van woorden en zinnen.
Stap 2: Het gebruik van een transformer
Een belangrijk aspect van een LLM is het gebruik van een transformerarchitectuur, een type neuraal netwerk dat de context van woorden begrijpt. In plaats woord voor woord in een tekst te bekijken, kan een transformer het verband zien tussen woorden in een zin, ongeacht waar die woorden staan. Dit is waarom dit soort moellen zo goed zijn in het geven van samenhangende en relevante antwoorden, die menselijk overkomen. Dit soort modellen heten vaak GPT-modellen (Generative Pre-trained Transformers).
Een neuraal netwerk is een complexe samenhang van lagen van knooppunten. Ieder knooppunt heeft een bepaalde waarde die tijdens het trainingsproces aangepast kan worden. Zo'n waarde heet een parameter. Wanneer je een model hebt wat uit meer parameters bestaat, is het een groter en complexer model, wat voor complexere vraagstukken kan worden ingezet, of wat nauwkeurigere antwoorden geeft.
Stap 3: Predictie en generatie
Wanneer je een vraag stelt aan een LLM (dit heet een "prompt"), voorspelt het model wat het meest waarschijnlijke antwoord is op basis van de patronen die het heeft geleerd tijdens de training. Het kan dit doen voor allerlei soorten vragen, van feitelijke vragen tot complexe probleemstellingen.
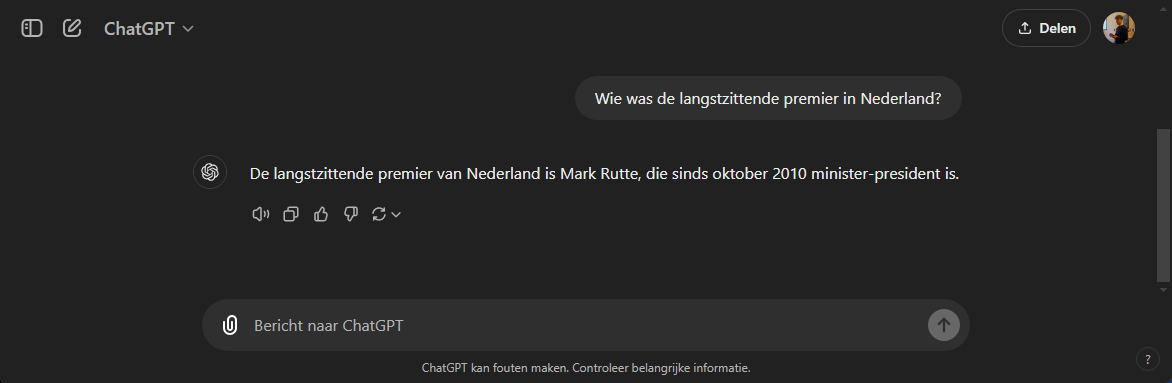
Daarbij kan het model zijn gebaseerd op verouderde data. Zie onderstaand voorbeeld waarbij Mark Rutte op moment van schrijven geen premier meer is.
3. Simpel voorbeeld: Afmaken van een zin
Laten we dit alles verduidelijken met een eenvoudig voorbeeld. Stel je voor dat je een large language model vraagt om de volgende zin af te maken:
_"De kat zit in de..."_
Het model kijkt naar de context en voorspelt waarschijnlijk iets als "zak", "doos", of "boom". Hoe doet het dat? Het model heeft geleerd dat in de meeste teksten waarin een kat voorkomt, deze vaak in een object zit dat past bij katten, zoals een boom of doos. Op basis van de patronen die het heeft herkend in zijn training, kiest het de meest waarschijnlijke voortzetting van de zin.
Hoe langer de zin, hoe meer context het model heeft om een passende aanvulling te genereren. Bijvoorbeeld, als je zegt:
_"De kat zit in de boom, en de hond..."_
Het model zal nu eerder iets voorspellen als: "...blaft naar de kat" of "...rent eromheen", omdat het geleerd heeft dat honden en katten vaak samen zo worden genoemd in verschillende teksten.
4. Waarom zijn Large Language Models zo groot?
De kracht van een LLM zit in de schaal waarop het is getraind. Een model zoals GPT-4 heeft miljarden tot zelfs triljoenen parameters. Deze parameters bevatten samen de kennis die het model heeft opgedaan uit de teksten die het heeft gezien. Hoe groter het model, hoe meer verbanden het kan leggen tussen woorden en contexten, en hoe beter het wordt in het genereren van realistische en nuttige teksten.
Door deze enorme schaal kan een LLM antwoorden geven op complexe vragen, teksten vertalen, artieklen schrijven, code genereren, etc.
5. Voorbeeld van een gesprek met een LLM
Om de werking van een LLM verder te verduidelijken, kijken we naar een praktisch voorbeeld. Stel dat je het volgende gesprek voert met een AI zoals ChatGPT:
Jij vraagt:
_"Wat is de hoofdstad van Frankrijk?"_
Het model antwoordt: _"De hoofdstad van Frankrijk is Parijs."_
Hoe weet het model dat? Tijdens de training heeft het model meermaals teksten gezien als "Parijs is de hoofdstad van Frankrijk" of varianten daarvan gezien, al dan niet in verschillende talen. Het herkent deze vraag dus onmiddellijk als een vraag naar een feitelijk antwoord, en het geeft het juiste antwoord.
Nu stel je een complexere vraag:
Jij vraagt: _"Kun je een kort verhaal schrijven over een schildpad die een avontuur beleeft?"_
Het model antwoordt: _"Op een mooie ochtend in het kleine dorpje aan de rand van het meer, ontdekte een nieuwsgierige schildpad genaamd Rolo iets bijzonders. Terwijl ze in de zon lag te slapen, zag ze een glanzend, vreemd object vallen uit de lucht. Het landde met een zachte plof in het gras. Rolo sprong op, haar ogen groot van nieuwsgierigheid..."_
Het model heeft geleerd hoe verhalen worden opgebouwd, welke woorden vaak in avonturen voorkomen, en hoe een logisch verloop van een verhaal eruitziet. Het kan dit toepassen op nieuwe prompts zoals deze.
6. Voorbeelden van toepassingen van Large Language Models
LLMs worden voor allerlei toepassingen ingezet, zowel bij privégebruik als in het bedrijfsleven. Hier zijn enkele voorbeelden:
- Chatbots en klantenservice: Veel bedrijven gebruiken LLM's om automatisch klantenservicevragen te beantwoorden.
- Contentgeneratie: LLM's kunnen helpen bij het schrijven van artikelen, blogs, en andere teksten, wat tijd en moeite bespaart voor schrijvers.
- Programmeren: Ontwikkelaars gebruiken LLM's zoals GitHub Copilot om automatisch codevoorstellen te krijgen tijdens het programmeren.
- Vertalen: LLM's kunnen worden gebruikt om teksten in verschillende talen te vertalen.
Conclusie
Een Large Language Model (LLM) is een specifieke techniek binnen kunstmatige intelligentie (generative AI). Een LLM kan teksten en opdrachten interpreteren en kan vervolgens nieuwe teksten genereren. Je geeft een opdracht (prompt) in menselijke taal, en krijgt daarop een begrijpbaar antwoord terug. De afgelopen jaren zijn er steeds betere LLMs ontwikkeld door bedrijven als OpenAI en Anthropic. Of het nu gaat om het opstellen van een persoonlijk trainingsschema, het schrijven van een verhaal, of het beantwoorden van vragen over code in een programmeertaal; een LLM kan worden ingezet voor allerlei verschillende toepassingen. Een LLM is daarbij altijd getraind op bestaande data, en kan daardoor in sommige gevallen verouderde antwoorden geven.
Nu je de basis van LLM's begrijpt, weet je beter hoe tools zoals ChatGPT werken en hoe ze je kunnen helpen in je werk of dagelijks leven.
Wil je allround AI expert worden?
Tijdens onze AI Opleiding leer je het hele AI spectrum kennen; van klassieke machine learning modellen tot generative AI met o.a. ChatGPT. Je leert programmeren in Python zodat je op uiteenlopende vlakken aan de slag kunt met AI.

Terry is afgestudeerd aan de TU Delft als ingenieur en heeft zich in zijn carrière beziggehouden met het optimaal benutten van data om bedrijfsprestaties te verbeteren. Dit heeft hij gedaan in verschillende rollen, als software ontwikkelaar en als data scientist.