Data Science Opleiding
incl. generative AI
Onze Data Science Opleiding (IABAC™ geaccrediteerd) leidt jou op tot expert in data science. De opleiding heeft een compleet programma: we starten met basis data science vaardigheden en eindigen met het zelf maken van machine learning modellen en duiken in de ontwikkelingen van generative AI. Na deze opleiding ben je in staat om zelfstandig te opereren als data scientist binnen jouw organisatie.
De data science opleiding biedt een combinatie van theorie en praktijk. Enerzijds diepen we het vakgebied data science uit en anderzijds ga je direct zelf aan de slag met het schrijven van scripts in Python. Zo breid je je theoretische kennis uit en bouw je al tijdens de opleiding nieuwe - direct in de praktijk toepasbare - vaardigheden op.
Tijdens deze data science opleiding werken we met Python. Voorkennis van programmeren is geen vereiste. Bij afronding ontvang je een officieel certificaat van deze IABAC™ geaccrediteerde opleiding.
Deelnemers over de Data Science Opleiding
John deed mee aan deze 4-daagse data science opleiding. Bekijk hier wat John over de opleiding te zeggen heeft.
Mandy deed mee aan de 10-daagse data science bootcamp. De eerste vier dagen van de bootcamp zijn identiek aan deze data science opleiding.
Leerdoelen Data Science Opleiding

Complete introductie in data science
In de eerste twee dagen maken we je vertrouwd met de mogelijkheden van Python en data science. We leggen alle basisvaardigheden voor data scientists uit middels opdrachten in onze eigen online omgeving. Je leert bijvoorbeeld om analyses te automatiseren en geavanceerde visualisaties te maken. Dit geeft je al voldoende basis om zelfstandig aan de slag te gaan in de praktijk.

Verdiepende kennis van machine learning
In de laatste twee dagen gaan we dieper in op machine learning & generative AI. Je leert welke modellen er zijn, wanneer je welk model moet toepassen en hoe je de modellen kunt beoordelen. Theorie en opdrachten wisselen elkaar hierbij af. Na de opleiding heb je een compleet overzicht van de mogelijkheden van data science en ben je in staat om zelf algoritmes te schrijven voor jouw organisatie.
Is deze data science opleiding wat voor mij?
Deze training is iets voor jou als:
- Je meer inzichten wilt halen uit beschikbare data binnen jouw werkomgeving.
- Je een beroep hebt waar veel databronnen en -analyses bij komen kijken en je je kennis wilt verbreden. Bijvoorbeeld in finance, logistiek, marketing, ICT, of HR.
Benodigde voorkennis
Er is geen specifieke voorkennis vereist, maar het is handig als je basiskennis van wiskunde hebt en ervaring hebt met bijvoorbeeld Excel files, tekstbestanden (csv) of databases. Het is een opleiding op uitdagend niveau en wij raden minimaal een afgeronde HBO opleiding aan.
Inhoud Data Science Opleiding
De inhoud van deze training is geaccrediteerd door de International Association of Business Analytics Certification (IABAC™).


Klik op onderstaande dagen om het programma in meer detail te zien.
Data science introductie
Je zult op dag één kennismaken met data science. Hoe is het vakgebied ontstaan en welke vaardigheden heeft een data scientist? We introduceren waarom Python dé programmeertaal is die centraal staat voor iedere data scientist. Je leert over de meestgebruikte 'data science packages'. Je zult direct tijdens deze eerste ochtend een eigen Python script schrijven en uitvoeren in onze eigen online omgeving.
Gedurende de eerste dag maak je je enkele basisvaardigheden eigen die essentieel zijn om te beheersen als data scientist. Deze vaardigheden gebruik je tevens de rest van de opleiding.
Basisvaardigheid #1: variabelen & datatypes
Wie werkt met data moet de data op kunnen slaan in variabelen. Zo kun je bijvoorbeeld getallen, reeksen, of tekst opslaan. In de data science opleiding leer je over welke datatypes relevant zijn voor data scientists. Je zult ervaren hoe verschillende datatypes tot andere mogelijkheden leiden.
Basisvaardigheid #2: Lists
Bij data science werkzaamheden kom je vaak enorme dataverzamelingen tegen. Een reeks van datapunten kan worden opgeslagen in een 'list'. We oefenen met lists en bespreken waar je lists in de dagelijkse praktijk voor gebruikt.
Basisvaardigheid #3: Dictionaries
Een dictionary is letterlijk een soort woordenboek. Je kunt aan de hand van de 'sleutels' in de dictionary bepaalde informatie opzoeken. Zo kun je bijvoorbeeld een dictionary maken waarin je plaatsnamen koppelt aan het aantal inwoners van die plaats. Als data scientist maak je dagelijks gebruik van dictionaries. We bespreken de toepassingen en oefenen met deze basisvaardigheid.
Basisvaardigheid #4: Logica, methoden en functies voor data science
In iedere data-analyse pas je logica toe op data. Python biedt een variatie aan mogelijkheden. We bespreken wanneer je logica toepast en oefenen ermee om het goed in de vingers te krijgen. Daarnaast leer je hoe je herhaaldelijke activiteiten in analyses versimpelt met het gebruik van functies. Je past zelf functies, methoden, en logica toe om de eerste ingewikkeldere inzichten uit data te halen.
Hiermee hebben we op de eerste dag een mooie basis gelegd waar we op door zullen bouwen op de volgende dagen.
Numpy: efficiënt met veel data werken
Als je wel eens met een grote dataset in Excel hebt gewerkt herken je misschien wel dat je al snel tegen de grenzen van het programma aanloopt. Met Python kun je met veel grotere datasets werken op een efficiëntere manier. NumPy is een Python package dat je in staat stelt om bewerkingen te doen op grote datasets.
Het NumPy package wordt bovendien veel gebruikt door andere data science packages. Het is daarom een onmisbaar onderdeel van iedere data science opleiding. We bespreken hoe je NumPy gebruikt en oefenen met een praktijkcasus.
Pandas: de belangrijkste data science tool
Pandas is veruit de meestgebruikte tool door data scientists. Je kunt met Pandas eigenlijk alles wat je in Excel kunt, plus een hele hoop meer. Zo kun je data importeren vanuit verschillende bronnen (denk aan Excel-bestanden, maar ook CSVs, APIs, of databases).
Vervolgens kun je deze data verkennen en bewerken op uiteenlopende manieren. Het is mogelijk om datasets te combineren, transformeren, groeperen, of filteren. Je kunt het zo gek niet bedenken of het is mogelijk in Pandas. We zullen uitgebreid stilstaan bij enkele praktijkoefeningen zodat je Pandas goed onder de knie krijgt.
Op dit punt in de opleiding ben je al in staat om uit data inzichten te halen die je onmogelijk met Excel had kunnen realiseren.
Matplotlib: mooie figuren plotten
Niet alleen het vergaren van nieuwe inzichten behoort tot de taken van een data scientist. Ook het overbrengen van nieuwe inzichten is een belangrijk onderdeel. En omdat niet iedereen even goed is met data, brengen veel data scientists inzichten over via grafieken/ figuren.
Met het Python package matplotlib leer je honderden verschillende soorten visualisaties te maken. Onderstaande afbeelding geeft een willekeurige indruk van de variatie in mogelijkheden.
In de data science opleiding leer je matplotlib toepassen in een praktijkcasus waarin je complexe, gepersonaliseerde visualisaties van de dataset maakt.
Eindopdracht
Tijdens een eindopdracht pas je alles wat je de eerste twee dagen hebt geleerd toe in één vraagstuk. Je zult diverse gegevensbronnen met elkaar verbinden, logica toepassen, functies schrijven, en werken in de packages NumPy, Pandas, en Matplotlib. Je haalt interessante inzichten uit de data en visualiseert deze inzichten zodat ook andere begrijpen wat je hebt gevonden.
Machine learning introductie
Machine learning is nu populairder dan ooit tevoren. We leggen uit hoe het vakgebied is ontstaan en hoe het zich heeft ontwikkeld. We schetsen een inzichtelijk beeld van het totale palet aan mogelijkheden. Zo bespreken we bijvoorbeeld wat supervised learning en unsupervised learning inhouden. Daarnaast gaan we in op wanneer je welk algoritme toepast.
Je leert welke stappen een data scientist doorloopt tijdens het bouwen van een machine learning model. Dit stappenplan zal tijdens de praktijkcases op dag 3 en 4 van de data science opleiding steeds gevolgd worden. Zo ontwikkel je gewenning met de stappen en wordt het jouw standaard werkwijze.
Classificatie, de theorie
Een classificatie algoritme kan voorspellen of een waarneming tot een bepaalde categorie of groep behoort. E-mails worden bijvoorbeeld beoordeeld door een classificatiemodel die berichten verdeelt in "spam" en "geen spam". We duiken in de onderliggende statistiek zodat je begrijpt wat er gebeurt in classificatiealgoritmes. We tonen diverse praktijkvoorbeelden en toepassingen. Daarnaast leer je welk Python package je voor dit type vraagstukken kunt gebruiken.
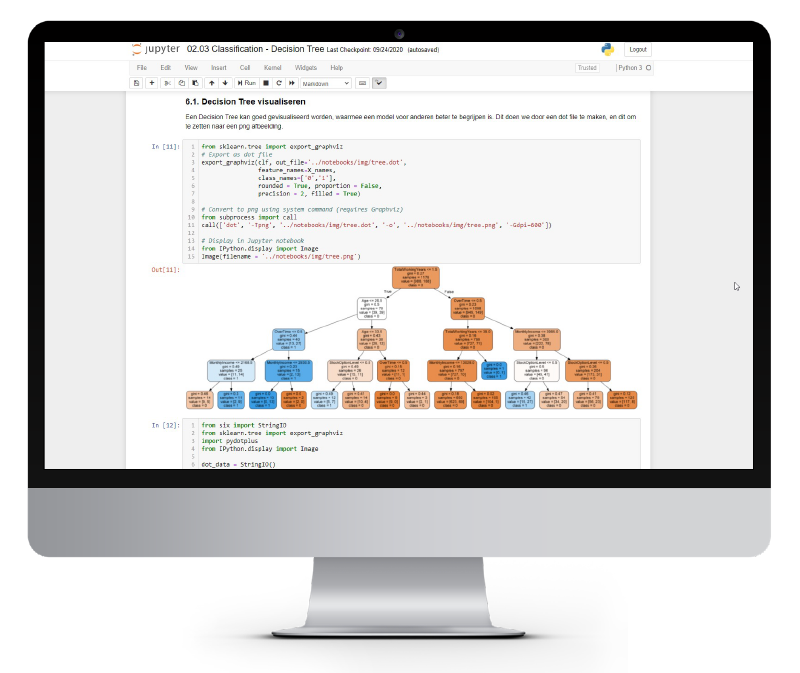
Classificatie, een praktijkcase
Gedurende de classificatie praktijkcase bouw je je eerste machine learning model zelf op. Dankzij de vaardigheden die je op dag 1 en 2 van de data science opleiding hebt opgedaan kun je een dataset importeren en verkennen. Zo maak je grafieken om verbanden in de data bloot te leggen die van belang zijn voor jouw machine learning model.
We gaan in op de mogelijkheden die je hebt als datasets niet compleet (missing values) of vervuild zijn. Je schrijft je eigen machine learning model, traint het model met een deel van je data. Vervolgens valideer je de kracht van het model door het voorspellingen te laten maken op nieuwe data.
Regressie, de theorie
Een regressie algoritme stelt je in staat om numerieke waarden te voorspellen. Denk hierbij bijvoorbeeld aan een voorspelling voor de levensverwachting op basis van iemand levensstijl. We diepen de statistiek en wiskunde achter regressieanalyses uit zodat je begrijpt wat er gebeurt als je machine learning modellen met deze algoritmes toepast. We bespreken diverse voorbeelden uit de praktijk en we vertellen welke mogelijkheden er binnen Python zijn voor de toepassing van regressie.
Regressie, een praktijkcase
Net als bij classificatie werken we ook bij regressie samen aan een mooie case en je bouwt hierbij van begin af aan je eigen model op. Dit begint met een ruwe dataset die je in Python importeert.
Je onderzoekt door de toepassing van een verkennende data-analyse welke factoren een belangrijke voorspellende waarde zouden kunnen spelen in jouw regressiemodel. Daarnaast leer je hoe je niet-numerieke data toch kunt gebruiken in regressiemodellen. We oefenen met meerdere regressiealgoritmes als linear regression en gradient boosting en kijken naar wanneer je welk algoritme kiest.
Unsupervised Learning en clustering
In dit onderdeel ontdek je wat unsupervised learning is en hoe het verschilt van supervised learning. We richten ons specifiek op clustering, een veelgebruikte techniek binnen unsupervised learning om groepen in data te vinden zonder vooraf gedefinieerde labels. Je leert hoe clusteringalgoritmes werken, zoals k-means clustering.
Generative AI (ChatGPT / Dall·E)
In dit onderdeel leer je wat generative AI is en hoe het verschilt van andere AI/ML-technieken. We geven je inzicht in de achterliggende principes en hoe deze technologie werkt. Daarnaast behandelen we de belangrijkste generatieve AI-modellen, zoals GPT en DALL·E, en tonen we hun indrukwekkende prestaties in het genereren van tekst en beelden. Je leert ook hoe je AI kunt "prompten" voor optimale resultaten. Tot slot demonstreren we praktische toepassingen, waarbij je met Python code zelf generative AI kunt inzetten voor text-to-text en text-to-image generaties.
Beoordelen en verbeteren van een model
Er zijn verschillende manieren om de prestatie van een model te meten. In de data science opleiding leer je welke dit zijn en wanneer je wat toepast. We kijken hierbij bijvoorbeeld naar een ROC curve, AUC en een confusion matrix. Met deze kennis gaan we terug naar je eerder gemaakte modellen en laten we zien wat het effect is van diverse verbeteringen met behulp van feature engineering en hyperparameter tuning.
Een model in productie brengen
Een model voegt pas echt waarde toe als het consequent wordt toegepast op nieuwe data. Denk hierbij bijvoorbeeld aan een voorspelling die automatisch wordt gegenereerd wanneer er nieuwe data in een database verschijnt. Je leert vanuit een praktijkvoorbeeld hoe je hier invulling aan kunt geven. Nieuwe gegevens kunnen tot een nieuwe situatie leiden waardoor de prestaties van je model met de tijd achteruit gaan. Je leert hoe je hier rekening mee kunt houden en hoe je dit voorkomt.
Eindopdracht
In een uitdagende eindopdracht pas je je nieuwe vaardigheden toe op een interessant vraagstuk vanuit een dataset uit de praktijk. Je combineert gegevens vanuit meerdere databronnen, voegt extra informatie toe met feature engineering, en stelt een model naar eigen keuze op wat je iteratief verbetert tot het aan de verwachtingen voldoet.
Zelfstudie add-ons
Naast het bovenstaande 4-daagse klassikale programma is het mogelijk om deze opleiding aan te vullen met zelfstudie add-ons. De kosten voor deze optionele add-ons bedragen €200 ex BTW. Het studiemateriaal plaatsen we in onze online omgeving en na de klassikale training kun je hier zelfstandig doorheen gaan. Onderstaande zelfstudie add-ons zijn momenteel beschikbaar voor deze training.
In deze zelfstudie add-on leer je hoe APIs zijn opgebouwd en hoe je met APIs kunt werken. Ook leer je hoe je vanuit Python werkt met SQL. Deelnemers die deze add-on kiezen zijn geïnteresseerd in hoe je data op uiteenlopende manieren kunt ophalen of weg kunt schrijven.
In deze add-on leer je om professionele code te schrijven. Je leert wat nodig is om binnen een professioneel team aan de slag te kunnen. Je staat stil bij geavanceerdere technieken om goede code te schrijven. Je sluit af met de manieren om code op een goede, betrouwbare manier te beheren.
In deze add-on leer je werken met ruimtelijke data vanuit Python. Je leert de belangrijkste packages om uiteindelijk ruimtelijke analyses, uiteenlopende bewerkingen en (interactieve) visualisaties te doen. Je leert o.a. werken met de populaire packages Shapely, GeoPandas, en Folium.
Locatie, data, en tijden
Deze Data Science Opleiding verzorgen we in Utrecht, Amsterdam, en Eindhoven. Alle ingeplande data en locaties vind je in het eerste veld van het inschrijfformulier. Trainingsdagen binnen om 09:30 en duren tot uiterlijk 16:30.
Download data science opleiding brochure
Ben je geïnteresseerd maar wil je je niet direct inschrijven? Download dan de opleidingsbrochure of neem een optie op de training en denk er rustig over na. Bij vragen kun je ons bereiken op 020 - 24 43 146. We helpen je graag verder.

Onze klanten















• 11, 12, 18 & 19 nov 2024 (VOL)
• 12, 13, 19 & 20 dec 2024
• 9, 10, 16 & 17 jan 2025
• 6, 7, 13 & 14 feb 2025
• 10, 11, 17 & 18 mrt 2025
• Alle geplande data in 2025 vind je in het inschrijfformulier