Op deze pagina wordt een omschrijving gegeven van een IMDb oefen dataset voor SQL. Deze dataset wordt toegepast in de uitleg van stukken query in de SQL blogs. De dataset die wordt gebruikt is een verkleinde variant van een oorspronkelijke dataset. De oorspronkelijke dataset heeft 7 tabellen, alleen sommige hiervan zijn verwijderd. Alleen de tabellen die essentieel zijn voor het uitleggen van de basis van SQL zijn namelijk behouden. Daarnaast is er een sample (selectief groepje rijen per tabel) gepakt van de volledige dataset. Er is een sample gepakt omdat dit minder geheugen in beslag neemt, resultaten makkelijker te interpreteren zijn en het minder complex overkomt op de gebruiker.
Internet Movie Database (IMDb)
De Internet Movie Database is een online databank met gegevens over films, televisieseries, acteurs en videogames. Het is een online platform die bijna iedereen wel kent. Op de website van IMDb kunnen mensen uitgebreide informatie vinden over films. De informatie die over de films te vinden zijn, is bijvoorbeeld welke cast en crew er hebben bijgedragen. Gebruikers kunnen op de website ook recensies schrijven en beoordelingen toevoegen.
Wil je zelf ook aan de slag met deze dataset? Hieronder staat een knop om deze dataset in een tekst bestand te downloaden. Deze stuk code is in een PostgreSQL stijl geschreven. Als je het in een relationeel database systeem gooit die deze taal ondersteund, krijg je de beschreven dataset.
Omschrijving van de dataset
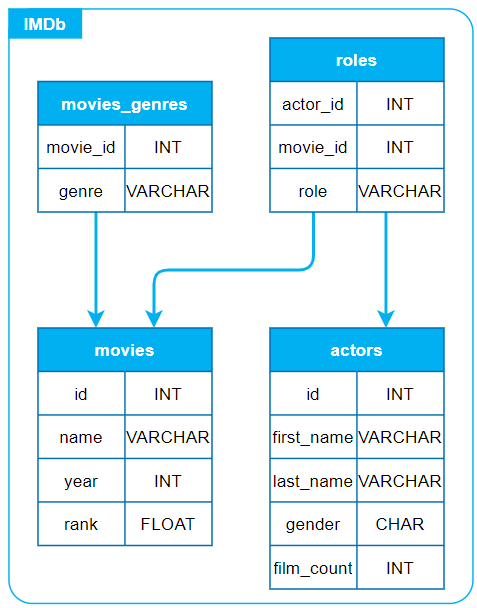
De dataset bestaat uit 4 verschillende tabellen; ‘movie’, ‘moviess_genres’, ‘actors’ en 'roles'. In de visualisatie van de dataset is te zien hoe deze gestructureerd is. De pijlen geven aan dat er informatie gerefereerd wordt vanuit een tabel naar een andere tabel. Iedere tabel heeft zijn eigen toevoegingen aan de dataset. Dit soort datasets worden ook wel relationele datasets genoemd.
‘movies’ is bijvoorbeeld de tabel die de basis informatie over alle films bevat. ‘movies_genres’ is de tabel die nog extra informatie over elke film heeft, namelijk het genre of de genres waar die bij hoort. ‘movies_genres’ is een aparte tabel omdat één film een of meerdere genres kan hebben, het is daarom niet mogelijk dit nog als extra kolom toe te voegen bij de tabel ‘movies’. ‘actors’ is de tabel die de basis informatie van alle acteurs bevat. ‘roles’ is de tabel die een link legt tussen de 'movies' en 'actors' tabel. Deze tabel heeft de informatie van welke acteur er in welke film een bepaalde rol heeft. De ‘roles’ tabel staat apart van ‘movies’ en ‘actors’ omdat in een film meerdere acteurs voorkomen en omdat één acteur meerdere rollen in zijn carrière kan hebben.
movies
id - Deze kolom is de primaire sleutel van de tabel. Elke rij heeft een unieke waarde hierin. Stel er zouden 2 films dezelfde naam hebben kun je ze onderscheiden door naar de kolom 'id' te kijken. Het datatype van deze kolom is INT, een geheel getal.
name - Deze kolom bevat de namen van alle films uit de dataset. Het datatype van deze kolom is VARCHAR, een variabel aantal karakters.
year - Deze kolom bevat het jaartal wanneer de film is uitgebracht. Het datatype van deze kolom is INT, een geheel getal.
rank - Deze kolom geeft de gemiddelde beoordeling van een film aan. Het datatype van deze kolom is FLOAT, een getal met decimalen.
| id | name | year | rank |
| 10920 | Aliens | 1986 | 8.2 |
| 17173 | Animal House | 1978 | 7.5 |
| 18979 | Apollo 13 | 1995 | 7.5 |
| ... | ... | ... | ... |
movies_genres
movie_id - Deze kolom geeft de id's weer van films. Deze kolom verwijst naar de 'id' kolom uit de movies tabel. In het voorbeeld hieronder is bijvoorbeeld te zien dan dat de film met id 10920 drie verschillende genres heeft. Als je kijkt naar de voorbeeld tabel van movies (hierboven), zie je dat de film met id: 10920, Aliens heet. Het datatype van deze kolom is INT, een geheel getal.
genre - Deze kolom bevat de informatie over welk genre iedere film heeft. Het datatype van deze kolom is VARCHAR, een variabel aantal karakters.
| movie_id | genre |
| 10920 | "Sci-Fi" |
| 10920 | "Action" |
| 10920 | "Thriller" |
| ... | ... |
actors
id - Deze kolom is de primaire sleutel van de tabel. Elke rij heeft een unieke waarde hierin, net zoals in de movies tabel. Het datatype van deze kolom is INT, een geheel getal.
first_name - Deze kolom bevat alle voornamen van de acteurs. Het datatype van deze kolom is VARCHAR, een variabel aantal karakters.
last_name - Deze kolom bevat alle achternamen van de acteurs. Het datatype van deze kolom is VARCHAR, een variabel aantal karakters.
gender - Deze kolom bevat het geslacht van de acteurs. Het datatype van deze kolom is CHAR(1). Dit wil zeggen dat er maar 1 karakter per rij in deze kolom voor kan komen. In deze dataset heeft deze kolom of de 'M' waarde of de 'F' waarde. 'M' staat hier voor male, oftewel man. 'F' staat hier voor female, oftewel vrouw.
film_count - Deze kolom bevat het aantal films waar een acteur aan heeft meegespeeld. Het datatype van deze kolom is INT, een geheel getal.
| id | first_name | last_name | gender | film_count |
| 933 | Lewis | Abernathy | M | 1 |
| 2547 | Andrew | Adamson | M | 1 |
| 2700 | William | Addy | M | 1 |
| ... | ... | ... | ... | ... |
roles
actor_id - Deze kolom bevat de id's van de acteurs. Deze kolom verwijst naar de id's van de tabel actors. Het datatype van deze kolom is INT, een geheel getal.
movie_id -Deze kolom bevat de id's van de movies. Deze kolom verwijst naar de id's van de tabel movies. Het datatype van deze kolom is INT, een geheel getal.
role - Deze kolom bevat de naam van de rol in de film. Het datatype van deze kolom is VARCHAR, een variabel aantal karakters.
| actor_id | movie_id | role |
| 16844 | 10920 | Lydecker |
| 36641 | 10920 | Russ Jorden |
| 42278 | 10920 | Cpl. Dwayne Hicks |
| ... | ... | ... |
Wil je alles begrijpen rond deze onderwerpen? Bekijk dan onze SQL cursus voor data analyse. Door middel van theorie en praktijkoefening wordt er een kwalitatieve basis gelegd. Nadat je deze training hebt gevolgd kun je zelfstandig verder aan de slag. Je kunt ook altijd even contact opnemen via info@datasciencepartners.nl of 020 - 24 43 146 als je een vraag hebt.